MaskRCNN 源码解读(Paddle)
tip
代码主要结合 PaddleDetection 的源码进行解读
MaskRCNN 简介
MaskRCNN 是一种基于 FasterRCNN 的实例分割模型,其主要思想是在 FasterRCNN 的基础上增加一个分支用于预测目标的 mask,其网络结构如下图所示:
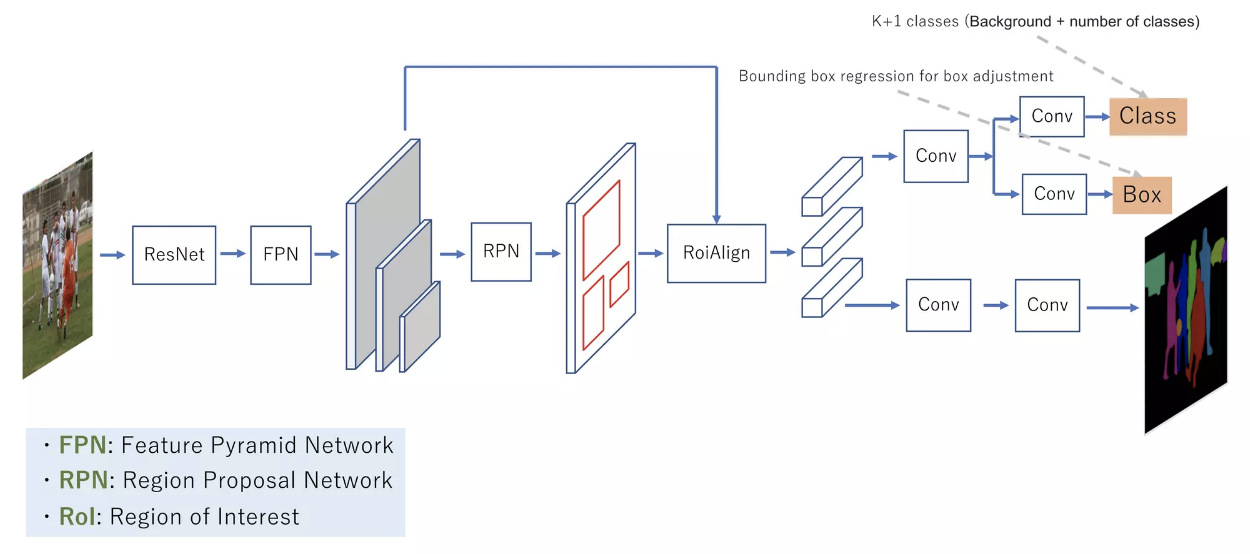
MaskRCNN 的核心组成部分有三个,分别是 RPN、RoIHead 和 MaskHead。RPN 层的主要作用是生成 RoI,RoIHead 层的主要作用是对 RoI 进行分类和回归,MaskHead 层的主要作用是对 RoI 进行 mask 预测。下面我们分别对这三个部分进行详细的介绍。
MaskRCNN 配置文件
PaddleDetection是一个基于PaddlePaddle开发的产业级目标检测开发套件,其配置文件的格式与Detectron2的配置文件格式基本一致,下面我们以PaddleDetection的配置文件为例,介绍MaskRCNN的配置文件。
# 模型配置
# 模型架构名称
architecture: MaskRCNN
# 预训练的骨干网络权重
# 从PaddleDet模型库中下载
pretrain_weights: https://paddledet.bj.bcebos.com/models/pretrained/ResNet50_cos_pretrained.pdparams
# Mask R-CNN模型组件
MaskRCNN:
# 骨干CNN网络
backbone: ResNet
# 区域提议网络头部
rpn_head: RPNHead
# 边界框回归头部
bbox_head: BBoxHead
# 掩码预测头部
mask_head: MaskHead
# 边界框后处理
bbox_post_process: BBoxPostProcess
# 掩码后处理
mask_post_process: MaskPostProcess
# ResNet骨干网络配置
ResNet:
# 使用ResNet-50
depth: 50
# 使用批规范化
norm_type: bn
# 冻结骨干网络到res2层
freeze_at: 0
# 返回从res2开始的特征图
return_idx: [2]
# 骨干网络中的层数
num_stages: 3
# 区域提议网络头部
RPNHead:
# 用于RPN的锚框生成器
anchor_generator:
# 锚框的长宽比
aspect_ratios: [0.5, 1.0, 2.0]
# 锚框尺寸
anchor_sizes: [32, 64, 128, 256, 512]
# 锚框步长
strides: [16]
# RPN训练的锚框分配
rpn_target_assign:
# 每张图像的批量大小
batch_size_per_im: 256
# 正样本的比例
fg_fraction: 0.5
# 负样本的重合度阈值
negative_overlap: 0.3
# 正样本的重合度阈值
positive_overlap: 0.7
# 如果正样本过多则随机采样
use_random: True
# 训练时的提议框生成
train_proposal:
# 丢弃低于此大小的提议框
min_size: 0.0
# 非极大抑制阈值
nms_thresh: 0.7
# NMS前的topk个提议框
pre_nms_top_n: 12000
# NMS后的topk个提议框
post_nms_top_n: 2000
# 汇聚所有FPN层后的topk个提议框
topk_after_collect: False
# 测试时的提议框生成
test_proposal:
# 丢弃低于此大小的提议框
min_size: 0.0
# 非极大抑制阈值
nms_thresh: 0.7
# NMS前的topk个提议框
pre_nms_top_n: 6000
# NMS后的topk个提议框
post_nms_top_n: 1000
# 边界框回归头部
BBoxHead:
# 使用Res5头部
head: Res5Head
# RoIAlign用于边界框特征提取
roi_extractor:
# 输出空间分辨率
resolution: 14
# RoIAlign的采样率
sampling_ratio: 0
# RoIAlign的输出对齐
aligned: True
# 训练时的边界框分配
bbox_assigner: BBoxAssigner
# 在全连接层前添加一个池化层
with_pool: true
# 边界框分配配置
BBoxAssigner:
# 每张图像的批量大小
batch_size_per_im: 512
# 背景阈值
bg_thresh: 0.5
# 前景阈值
fg_thresh: 0.5
# 正样本的比例
fg_fraction: 0.25
# 如果正样本过多则随机采样
use_random: True
# 边界框后处理
BBoxPostProcess:
# 回归后解码边界框
decode: RCNNBox
# 多类非极大抑制
nms:
# NMS名称
name: MultiClassNMS
# NMS后保留的topk个数
keep_top_k: 100
# 置信度阈值
score_threshold: 0.05
# IOU阈值
nms_threshold: 0.5
# 掩码预测头部
MaskHead:
# 掩码特征层
head: MaskFeat
# RoIAlign用于掩码特征提取
roi_extractor:
# 输出空间分辨率
resolution: 14
# RoIAlign采样率
sampling_ratio: 0
# RoIAlign输出对齐
aligned: True
# 训练时的掩码分配
mask_assigner: MaskAssigner
# 与边界框头部共享卷积特征
share_bbox_feat: true
# 掩码卷积层
MaskFeat:
# 卷积层数
num_convs: 0
# 输出通道数
out_channel: 256
# 掩码分配配置
MaskAssigner:
# 掩码输出分辨率
mask_resolution: 14
# 掩码后处理
MaskPostProcess:
# 二值化掩码的阈值
binary_thresh: 0.5
好的,这里详细介绍一下这个Mask R-CNN配置文件中每个模块的作用:
Backbone (骨干网络):ResNet backbone用于从输入图像中提取特征图。这里使用ResNet-50,经过卷积和下采样提取了不同尺度的语义特征。
RPN (区域提议网络) :RPN使用滑动窗口在backbone特征图上生成候选区域提议,提议可能包含潜在的物体。RPNHead产生anchor并对其进行refine。
RoI Align:将提议区域映射到backbone特征图上,采用RoI Align进行池化,获得固定长度的特征向量。
BBox Head:边界框回归分支,用于精炼提议框的坐标,使其更准确地预测物体边界框。
BBox Predictor:根据bbox head特征,预测物体类别和边界框坐标调整量。
BBox Assigner:训练时为提议框分配正负样本,用于训练BBox Predictor。
BBox Post Process:对预测的边界框执行解码和NMS,生成最后检测结果。
Mask Head:Mask分支,用于根据精炼后的提议框预测相应的物体掩码。
Mask Predictor:预测物体掩码图。
Mask Assigner:训练时为提议框分配真值掩码用于训练Mask Predictor。
Mask Post Process:对预测的掩码进行后处理,生成物体的二值掩码结果。
以上模块组合完成从RPN生成候选框,到精炼提议框和预测物体类别、边界框和掩码的整个流程。
下面我们会逐个模块进行详细介绍。
MaskRCNN 主模型
在 PaddleDetection/ppdet/modeling/architectures/mask_rcnn.py 中定义了 MaskRCNN 的主模型,其的定义代码如下:
@register
class MaskRCNN(BaseArch):
"""
Mask R-CNN网络,参考论文https://arxiv.org/abs/1703.06870
参数:
backbone (object): 骨干网络实例
rpn_head (object): RPN头部实例
bbox_head (object): 边界框回归头部实例
mask_head (object): 掩码预测头部实例
bbox_post_process (object): 边界框后处理实例
mask_post_process (object): 掩码后处理实例
neck (object): FPN网络实例
"""
category = 'architecture'
inject = [
'bbox_post_process',
'mask_post_process',
]
def __init__(self,
backbone,
rpn_head,
bbox_head,
mask_head,
bbox_post_process,
mask_post_process,
neck=None):
# 初始化基类
super(MaskRCNN, self).__init__()
# 骨干网络
self.backbone = backbone
# FPN颈部网络
self.neck = neck
# RPN头部
self.rpn_head = rpn_head
# 边界框回归头部
self.bbox_head = bbox_head
# 掩码预测头部
self.mask_head = mask_head
# 边界框后处理
self.bbox_post_process = bbox_post_process
# 掩码后处理
self.mask_post_process = mask_post_process
当调用 mask rcnn 模型的时候会调用 __init__ 函数,其会初始化骨干网络、FPN网络、RPN头部、边界框回归头部、掩码预测头部、边界框后处理和掩码后处理等模块。然后在 forward 函数中会调用这些模块进行前向计算,其代码如下:
def _forward(self):
# 获取骨干网络特征
body_feats = self.backbone(self.inputs)
# 通过FPN获取多尺度特征
if self.neck is not None:
with profiler.RecordEvent(name="MaskRCNN::neck"):
body_feats = self.neck(body_feats)
# 训练模式
if self.training:
# RPN头部生成提议框
rois, rois_num, rpn_loss = self.rpn_head(body_feats, self.inputs)
# 边界框回归头部损失和特征
bbox_loss, bbox_feat = self.bbox_head(body_feats, rois, rois_num, self.inputs)
# 获取精炼后的提议框
rois, rois_num = self.bbox_head.get_assigned_rois()
bbox_targets = self.bbox_head.get_assigned_targets()
# 掩码头部损失
# 掩码头部需要bbox_feat
mask_loss = self.mask_head(body_feats, rois, rois_num, self.inputs,
bbox_targets, bbox_feat)
# 返回损失
return rpn_loss, bbox_loss, mask_loss
# 测试模式
else:
rois, rois_num, _ = self.rpn_head(body_feats, self.inputs)
# 边界框预测
preds, feat_func = self.bbox_head(body_feats, rois, rois_num, None)
# 获取图像信息
im_shape = self.inputs['im_shape']
scale_factor = self.inputs['scale_factor']
# 边界框后处理
bbox, bbox_num, nms_keep_idx = self.bbox_post_process(
preds, (rois, rois_num), im_shape, scale_factor)
# 掩码预测
mask_out = self.mask_head(
body_feats, bbox, bbox_num, self.inputs, feat_func=feat_func)
# 将预测结果映射回原图像
bbox, bbox_pred, bbox_num = self.bbox_post_process.get_pred(
bbox, bbox_num, im_shape, scale_factor)
origin_shape = self.bbox_post_process.get_origin_shape()
mask_pred = self.mask_post_process(mask_out, bbox_pred, bbox_num, origin_shape)
# 记录附加输出数据
if self.use_extra_data:
extra_data = {}
extra_data['scores'] = preds[1] # 预测得分
extra_data['nms_keep_idx'] = nms_keep_idx # NMS前的索引
# 返回预测结果
if self.use_extra_data:
return bbox_pred, bbox_num, mask_pred, extra_data
else:
return bbox_pred, bbox_num, mask_pred
在训练模式下,会调用 RPN 头部生成提议框,然后调用边界框回归头部生成边界框,最后调用掩码预测头部生成掩码。在测试模式下,会调用 RPN 头部生成提议框,然后调用边界框回归头部生成边界框,最后调用掩码预测头部生成掩码。下面我们分别对这些模块进行详细的介绍。
RPN Head
Mask RCNN模型中,RPNHead的主要作用是:
- 生成区域提议框(Region Proposals):RPNHead中的主干网络会输出一个特征图,RPNHead会在这个特征图的每个像素位置上设置多个锚框(anchors)。然后通过一个小的卷积网络对每个锚框预测它包含目标的概率以及坐标调整量。根据这些预测结果,过滤掉大部分背景 anchors,输出最可能包含前景目标的区域提议框。这是RPN的核心功能。
- 提供ROI Align的输入:RPN生成的提议框会作为ROI Align模块的输入,ROI Align会根据这些提议框在原始特征图上截取对应感受野,输出定长的小特征图。这是Mask RCNN区分前景背景的关键一步。
- 训练RPN网络:在训练时,RPNHead还会计算提议框和真值框的匹配情况,定义RPN网络的分类loss和回归loss,通过反向传播训练网络。
这样可以让RPNHead学习到生成高质量提议框的能力。
RPN head 定义在 PaddleDetection/ppdet/modeling/proposal_generator/rpn_head.py 中。我们首先先来看一下 RPN head 的初始化函数:
@register
class RPNHead(nn.Layer):
"""
区域提议网络(Region Proposal Network)
参数:
anchor_generator (dict): 锚框生成器配置
rpn_target_assign (dict): RPN目标分配配置
train_proposal (dict): 训练时提议框生成配置
test_proposal (dict): 测试时提议框生成配置
in_channel (int): 输入特征图通道数
"""
shared = ['export_onnx']
inject = ['loss_rpn_bbox']
def __init__(self,
anchor_generator=_get_class_default_kwargs(AnchorGenerator),
rpn_target_assign=_get_class_default_kwargs(RPNTargetAssign),
train_proposal=_get_class_default_kwargs(ProposalGenerator,
12000, 2000),
test_proposal=_get_class_default_kwargs(ProposalGenerator),
in_channel=1024,
export_onnx=False,
loss_rpn_bbox=None):
# 初始化基类
super(RPNHead, self).__init__()
# 解析配置生成实例
self.anchor_generator = parse_anchor_generator(anchor_generator)
self.rpn_target_assign = parse_rpn_target_assign(rpn_target_assign)
self.train_proposal = parse_proposal_generator(train_proposal)
self.test_proposal = parse_proposal_generator(test_proposal)
# 是否导出ONNX
self.export_onnx = export_onnx
# RPN损失函数
self.loss_rpn_bbox = loss_rpn_bbox
# 锚框数量
num_anchors = self.anchor_generator.num_anchors
# RPN特征提取模块
self.rpn_feat = RPNFeat(in_channel, in_channel)
# RPN预测模块
self.rpn_rois_score = nn.Conv2D(...) # 分类得分
self.rpn_rois_delta = nn.Conv2D(...) # 回归偏移量
这里面的 anchor_generator 和 rpn_target_assign 需要详细注意:
anchor_generator:
- 它定义了RPN网络使用的锚框尺寸和比例,锚框数量等参数。
- AnchorGenerator会根据这些配置,在每个像素位置上生成多个锚框,覆盖整个输入特征图。
- 一般会设置多种尺度和长宽比的锚框,以适应不同形状、大小的目标物体。
- anchor_generator是RPN的核心组成部分,直接决定了模型对不同尺度目标的检测能力。
rpn_target_assign:
- 它定义了将RPN生成的 anchors 和真实标注框(ground truth bboxes)匹配为正负样本的规则。
- 例如IoU大于0.7匹配为正样本,小于0.3为负样本。
- rpn_target_assign 还会为每个正样本分配回归目标,即标注框与anchors的偏移量。
- 这些正负样本标注和回归目标将在RPN头的损失函数中使用,指导网络优化。
- rpn_target_assign影响RPN对小目标、遮挡目标的检测效果。规则合理则效果好。
综上,anchor_generator 和 rpn_target_assign 在RPN网络生成有效训练样本上起关键作用。其参数设置会直接影响模型检测小目标、不同形状目标的效果。
下面我们来解析一下 RPN Head 整个 Forward 的流程:
forward
# feats: 输入的特征图
# inputs: 其它输入,如图像尺寸等
def forward(self, feats, inputs):
# 通过RPN特征提取模块提取特征
rpn_feats = self.rpn_feat(feats)
# 初始化保存预测结果的列表
scores = []
deltas = []
# 对每个特征图进行预测
for rpn_feat in rpn_feats:
# 通过分类分支预测各个anchor的 Obj Score
rrs = self.rpn_rois_score(rpn_feat)
# 通过回归分支预测各个anchor的坐标调整量
rrd = self.rpn_rois_delta(rpn_feat)
# 将预测结果保存到列表中
scores.append(rrs)
deltas.append(rrd)
# 生成各个特征图上的全部anchors
anchors = self.anchor_generator(rpn_feats)
# 根据预测结果生成提议框
rois, rois_num = self._gen_proposal(scores, deltas, anchors, inputs)
# 训练阶段
if self.training:
# 计算RPN损失函数
loss = self.get_loss(scores, deltas, anchors, inputs)
return rois, rois_num, loss
# 推理阶段
else:
return rois, rois_num, None
上面的代码主要包含如下的几个步骤:
输入特征图转为RPN特征
RPN头中加入了一个特征提取模块rpn_feat,对输入的backbone特征进一步提取,以得到更加适合RPN任务的特征表示。
这可以增强特征的表达能力,提升RPN的预测精度。
对每个特征图进行分类分数和回归预测
RPN的任务是对各个锚框预测它是否包含物体以及框的精确坐标。
所以针对每个特征图,分别通过两个卷积分支rpn_rois_score和rpn_rois_delta predicting 输出分类分数和坐标回归结果。
生成锚框
根据预设的anchors尺寸和特征图大小,在每个像素位置上生成多个锚框anchors。
这为RPN提供大量先验框,覆盖各种形状和大小的潜在目标。
根据预测和锚框生成提议框
- 将预测的分类分数和回归量应用到锚框上,过滤和调整锚框,生成毗邻真实目标的高质量的RoIs。
- 这是RPN模块的核心输出。
训练时计算RPN损失
- 使用预测结果和标注的目标框真值计算分类损失和回归损失,优化RPN网络。
- 使RPN可以区分前景背景,并回归到真值框。
推理时直接返回提议框
- 不需要训练,直接输出提议框结果进行后续检测。
RPN头的各个步骤均对提升RPN检测小目标、准确定位具有重要作用。 上面的代码里 _gen_proposal 函数是用来生成提议框的,其代码如下:
_gen_proposal
def _gen_proposal(self, scores, bbox_deltas, anchors, inputs):
"""
scores (list[Tensor]): Multi-level scores prediction
bbox_deltas (list[Tensor]): Multi-level deltas prediction
anchors (list[Tensor]): Multi-level anchors
inputs (dict): ground truth info
"""
prop_gen = self.train_proposal if self.training else self.test_proposal
im_shape = inputs['im_shape']
# 保存每个batch的提议框结果
bs_rois_collect = []
bs_rois_num_collect = []
# 获取batch大小
batch_size = paddle.shape(im_shape)[0]
# 对每个batch单独生成提议框
for i in range(batch_size):
# 保存每个级别的提议框
rpn_rois_list = []
rpn_prob_list = []
rpn_rois_num_list = []
# 对每一层的特征循环
for rpn_score, rpn_delta, anchor in zip(scores, bbox_deltas, anchors):
# 生成当前特征层的提议框
rpn_rois, rpn_rois_prob, rpn_rois_num, post_nms_top_n = prop_gen(
scores=rpn_score[i:i+1],
bbox_deltas=rpn_delta[i:i+1],
anchors=anchor,
im_shape=im_shape[i:i+1]
)
# 保存当前级别的结果
rpn_rois_list.append(rpn_rois)
rpn_prob_list.append(rpn_rois_prob)
rpn_rois_num_list.append(rpn_rois_num)
# 多个级别情况下,拼接各级别的提议框
if len(scores) > 1:
rpn_rois = paddle.concat(rpn_rois_list)
rpn_prob = paddle.concat(rpn_prob_list).flatten()
# 截取topk个提议框
num_rois = paddle.shape(rpn_prob)[0].cast('int32')
if num_rois > post_nms_top_n:
topk_prob, topk_inds = paddle.topk(rpn_prob, post_nms_top_n)
topk_rois = paddle.gather(rpn_rois, topk_inds)
else:
topk_rois = rpn_rois
topk_prob = rpn_prob
# 单级别情况下直接取结果
else:
topk_rois = rpn_rois_list[0]
topk_prob = rpn_prob_list[0].flatten()
# 保存当前batch的结果
bs_rois_collect.append(topk_rois)
bs_rois_num_collect.append(paddle.shape(topk_rois)[0])
# 拼接每个batch的提议框数量
bs_rois_num_collect = paddle.concat(bs_rois_num_collect)
# 返回结果
if self.export_onnx:
# ...
else:
output_rois = bs_rois_collect
output_rois_num = bs_rois_num_collect
return output_rois, output_rois_num
output_rois 会作为 ROI Align 的输入,用于从原始特征图中截取提议框感受野,生成ROI特征。rois_num会用于统计每张图像的实际提议框数量。
get_loss
如果是训练阶段的话,会调用 get_loss 函数计算 RPN 的损失函数,其代码如下:
def get_loss(self, pred_scores, pred_deltas, anchors, inputs):
"""
计算RPN(Region Proposal Network)的损失函数
Args:
pred_scores (list[Tensor]): 多层级别的分数预测
pred_deltas (list[Tensor]): 多层级别的位置偏移预测
anchors (list[Tensor]): 多层级别的锚框
inputs (dict): 包含真实标注信息的字典,包括图像(im)、真实边界框(gt_bbox)、真实分数(gt_score)
Returns:
dict: 包含损失值的字典,包括分类损失('loss_rpn_cls')和位置回归损失('loss_rpn_reg')
"""
# 将锚框的形状重塑为(-1, 4),将多层级别的锚框合并成一个列表
anchors = [paddle.reshape(a, shape=(-1, 4)) for a in anchors]
anchors = paddle.concat(anchors)
# 对分数预测进行相应的处理,以便进行计算
scores = [
paddle.reshape(
paddle.transpose(
v, perm=[0, 2, 3, 1]),
shape=(v.shape[0], -1, 1)) for v in pred_scores
]
scores = paddle.concat(scores, axis=1)
# 对位置偏移预测进行相应的处理,以便进行计算
deltas = [
paddle.reshape(
paddle.transpose(
v, perm=[0, 2, 3, 1]),
shape=(v.shape[0], -1, 4)) for v in pred_deltas
]
deltas = paddle.concat(deltas, axis=1)
# 使用RPN目标分配函数获取目标分数、边界框、位置目标以及归一化参数
score_tgt, bbox_tgt, loc_tgt, norm = self.rpn_target_assign(inputs, anchors)
# 将分数和位置偏移重塑为一维张量
scores = paddle.reshape(x=scores, shape=(-1, ))
deltas = paddle.reshape(x=deltas, shape=(-1, 4))
# 停止梯度计算目标分数
score_tgt = paddle.concat(score_tgt)
score_tgt.stop_gradient = True
# 创建正样本掩码和对应的索引
pos_mask = score_tgt == 1
pos_ind = paddle.nonzero(pos_mask)
# 创建有效样本掩码和对应的索引
valid_mask = score_tgt >= 0
valid_ind = paddle.nonzero(valid_mask)
# 计算分类损失
if valid_ind.shape[0] == 0:
loss_rpn_cls = paddle.zeros([1], dtype='float32')
else:
score_pred = paddle.gather(scores, valid_ind)
score_label = paddle.gather(score_tgt, valid_ind).cast('float32')
score_label.stop_gradient = True
loss_rpn_cls = F.binary_cross_entropy_with_logits(
logit=score_pred, label=score_label, reduction="sum")
# 计算位置回归损失
if pos_ind.shape[0] == 0:
loss_rpn_reg = paddle.zeros([1], dtype='float32')
else:
loc_pred = paddle.gather(deltas, pos_ind)
loc_tgt = paddle.concat(loc_tgt)
loc_tgt = paddle.gather(loc_tgt, pos_ind)
loc_tgt.stop_gradient = True
if self.loss_rpn_bbox is None:
loss_rpn_reg = paddle.abs(loc_pred - loc_tgt).sum()
else:
loss_rpn_reg = self.loss_rpn_bbox(loc_pred, loc_tgt).sum()
# 返回包含损失值的字典,同时对损失值进行归一化
return {
'loss_rpn_cls': loss_rpn_cls / norm,
'loss_rpn_reg': loss_rpn_reg / norm
}
BBox Head
在Mask R-CNN中,bbox head(边界框头部)的主要作用是执行边界框(bounding box)的回归任务。具体来说,bbox head负责从区域提议(region proposals)中精确地预测出目标对象的边界框坐标。以下是bbox head的主要作用和功能:
- 边界框回归: bbox head接受来自区域提议(通常是RPN产生的锚框)的特征图作为输入,并在每个区域提议上执行边界框的回归。它会根据输入的特征图和先前的卷积层学习如何调整每个提议的位置,以更准确地拟合目标对象的边界框。
- 目标检测: 一旦bbox head完成边界框回归,它还可以根据回归的边界框坐标提供目标检测的结果。这些边界框通常包含了概率最高的目标类别,因此bbox head也可以用于执行物体检测任务。
- 边界框修正: bbox head可以校正区域提议中的边界框,使其更加精确,从而提高物体检测的准确性。这是因为在区域提议生成过程中,可能会存在一些误差或不准确的边界框。
- 用于实例分割: 在Mask R-CNN中,bbox head通常是实例分割(Instance Segmentation)任务的一部分。一旦获得了边界框的预测,这些边界框可以用于提取与每个实例相关的感兴趣区域(Region of Interest,ROI),然后在ROI上执行像素级的分割,以获取每个实例的精确掩码。
bbox head 定义在 ppdet/modeling/heads/bbox_head.py 中。我们首先先来看一下 bbox head 的初始化函数:
@register
class BBoxHead(nn.Layer):
__shared__ = ['num_classes', 'use_cot']
__inject__ = ['bbox_assigner', 'bbox_loss', 'loss_cot']
"""
RCNN bbox head
Args:
head (nn.Layer): bbox头部的特征提取器
in_channel (int): RoI提取器之后的输入通道数
roi_extractor (object): RoI Extractor的模块
bbox_assigner (object): Box Assigner的模块,用于为边界框分配标签和样本
with_pool (bool): 是否使用池化来提取RoI特征
num_classes (int): 类别数
bbox_weight (List[float]): 获取解码边界框的权重
cot_classes (int): 基础类别数
loss_cot (object): Label-cotuning的模块
use_cot(bool): 是否使用Label-cotuning
"""
def __init__(self,
head,
in_channel,
roi_extractor=_get_class_default_kwargs(RoIAlign),
bbox_assigner='BboxAssigner',
with_pool=False,
num_classes=80,
bbox_weight=[10., 10., 5., 5.],
bbox_loss=None,
loss_normalize_pos=False,
cot_classes=None,
loss_cot='COTLoss',
use_cot=False):
super(BBoxHead, self).__init__()
# 初始化BBoxHead的各种属性
self.head = head # 特征提取器
self.roi_extractor = roi_extractor # RoI特征提取器
if isinstance(roi_extractor, dict):
self.roi_extractor = RoIAlign(**roi_extractor) # 如果是字典,则创建RoIAlign对象
self.bbox_assigner = bbox_assigner # 边界框分配器
self.with_pool = with_pool # 是否使用池化
self.num_classes = num_classes # 类别数
self.bbox_weight = bbox_weight # 解码边界框的权重
self.bbox_loss = bbox_loss # 边界框损失
self.loss_normalize_pos = loss_normalize_pos # 是否标准化正样本的损失
self.loss_cot = loss_cot # Label-cotuning的损失
self.cot_relation = None
self.cot_classes = cot_classes # 基础类别数
self.use_cot = use_cot # 是否使用Label-cotuning
# 如果使用Label-cotuning,定义BBoxHead中的评分预测线性层和边界框评分线性层
if use_cot:
self.cot_bbox_score = nn.Linear(
in_channel,
self.num_classes + 1,
weight_attr=paddle.ParamAttr(initializer=Normal(
mean=0.0, std=0.01)))
self.bbox_score = nn.Linear(
in_channel,
self.cot_classes + 1,
weight_attr=paddle.ParamAttr(initializer=Normal(
mean=0.0, std=0.01)))
self.cot_bbox_score.skip_quant = True # 跳过量化(quantization)
else:
self.bbox_score = nn.Linear(
in_channel,
self.num_classes + 1,
weight_attr=paddle.ParamAttr(initializer=Normal(
mean=0.0, std=0.01)))
self.bbox_score.skip_quant = True # 跳过量化
# 定义边界框偏移预测的线性层
self.bbox_delta = nn.Linear(
in_channel,
4 * self.num_classes,
weight_attr=paddle.ParamAttr(initializer=Normal(
mean=0.0, std=0.001)))
self.bbox_delta.skip_quant = True # 跳过量化
self.assigned_label = None # 分配的标签
self.assigned_rois = None # 分配的RoIs
bbox head 的前向计算函数如下:
forward
def forward(self, body_feats=None, rois=None, rois_num=None, inputs=None, cot=False):
"""
MASK RCNN bbox head的前向传播函数
Args:
body_feats (list[Tensor]): 来自骨干网络的特征图列表
rois (list[Tensor]): 由RPN模块生成的感兴趣区域(RoIs)
rois_num (Tensor): 每个图像中的RoI数量
inputs (dict{Tensor}): 图像的真实标注信息
cot (bool): 是否使用Label-cotuning
Returns:
Tensor or dict: 如果在训练模式下,返回损失和bbox头部的特征图;如果在推断模式下,返回预测结果和bbox头部的特征图
"""
# 如果处于训练模式
if self.training:
# 进行RoI分配,获取分配后的RoIs、RoI数量和目标标签
rois, rois_num, targets = self.bbox_assigner(rois, rois_num, inputs)
self.assigned_rois = (rois, rois_num)
self.assigned_targets = targets
# 使用RoI特征提取器提取RoI特征
rois_feat = self.roi_extractor(body_feats, rois, rois_num)
# 使用bbox头部提取更高级的RoI特征
bbox_feat = self.head(rois_feat)
# 如果设置了使用池化,则进行自适应平均池化
if self.with_pool:
feat = F.adaptive_avg_pool2d(bbox_feat, output_size=1)
feat = paddle.squeeze(feat, axis=[2, 3])
else:
feat = bbox_feat
# 如果使用Label-cotuning,计算分数
if self.use_cot:
scores = self.cot_bbox_score(feat) # Label-cotuning分数
cot_scores = self.bbox_score(feat) # 常规分数
else:
scores = self.bbox_score(feat) # 常规分数
# 计算边界框位置偏移
deltas = self.bbox_delta(feat)
# 如果处于训练模式
if self.training:
# 计算损失函数,包括分类损失和位置回归损失
loss = self.get_loss(
scores,
deltas,
targets,
rois,
self.bbox_weight,
loss_normalize_pos=self.loss_normalize_pos)
# 如果存在Label-cotuning关系,计算Label-cotuning损失
if self.cot_relation is not None:
loss_cot = self.loss_cot(cot_scores, targets, self.cot_relation)
loss.update(loss_cot) # 将Label-cotuning损失添加到总损失中
return loss, bbox_feat # 返回损失和bbox头部的特征图
else:
# 如果处于推断模式
if cot:
pred = self.get_prediction(cot_scores, deltas) # 获取预测结果
else:
pred = self.get_prediction(scores, deltas) # 获取预测结果
return pred, self.head # 返回预测结果和bbox头部的特征图
bbox_assigner
bbox_assigner 是在目标检测模型中用于分配RoIs(Region of Interest)的模块或组件,其主要作用是将生成的RoIs与真实标注的目标之间建立联系,为每个RoI分配一个类别标签和指示正负样本的标志,以供训练目标检测模型时使用。以下是 bbox_assigner 的主要作用和功能:
RoI分配: Bbox_assigner会根据生成的RoIs以及它们与真实目标的重叠程度,将每个RoI分配给一个类别标签(如目标类别、背景等)。这个过程通常涉及到计算RoIs与真实目标之间的IoU(交并比)以确定最佳匹配。
正负样本标记: 除了为RoIs分配类别标签外,bbox_assigner还会将每个RoI标记为正样本或负样本。正样本通常是那些与真实目标有足够重叠的RoIs,而负样本则是那些与真实目标没有足够重叠的RoIs。
RoI采样: Bbox_assigner还可以决定在训练过程中使用哪些RoIs。通常,它会执行正负样本采样,以确保正负样本之间的平衡,以及减少训练时的计算负担。
目标标签生成: 在训练目标检测模型时,bbox_assigner还会生成与RoIs对应的真实目标标签信息,以供损失函数的计算。这些标签通常包括类别标签和边界框的真实坐标。
下面我们看一下 bbox_assigner 的实现代码:
@register
class BBoxAssigner(object):
__shared__ = ['num_classes', 'assign_on_cpu']
"""
RCNN targets assignment module(目标分配模块)
分配包括三个步骤:
1. 匹配RoIs(感兴趣区域)和真实边界框,为RoIs分配前景或背景样本标签
2. 对RoIs进行采样,以保持前景和背景之间的适当比例
3. 为分类和回归分支生成目标
Args:
batch_size_per_im (int): 每张图像的RoIs总数,默认512
fg_fraction (float): 前景RoIs所占比例,默认0.25
fg_thresh (float): RoI与真实边界框之间的最小重叠度,用于将RoI标记为前景样本,默认0.5
bg_thresh (float): RoI与真实边界框之间的最大重叠度,用于将RoI标记为背景样本,默认0.5
ignore_thresh(float): 如果大于零,则用于忽略is_crowd的真实边界框
use_random (bool): 是否使用随机采样来选择前景和背景边界框,默认为True
cascade_iou (list[iou]): 在级联RCNN中使用的一组重叠度,用于每个阶段选择前景和背景,默认为[0.5, 0.6, 0.7]
num_classes (int): 类别数
assign_on_cpu (bool): 如果真实边界框数量过多,是否在CPU上计算IoU(交并比),默认为False
"""
def __init__(self,
batch_size_per_im=512,
fg_fraction=.25,
fg_thresh=.5,
bg_thresh=.5,
ignore_thresh=-1.,
use_random=True,
cascade_iou=[0.5, 0.6, 0.7],
num_classes=80,
assign_on_cpu=False):
super(BBoxAssigner, self).__init__()
# 初始化BBoxAssigner的各种属性
self.batch_size_per_im = batch_size_per_im # 每张图像的RoIs总数
self.fg_fraction = fg_fraction # 前景RoIs所占比例
self.fg_thresh = fg_thresh # 前景RoI的最小重叠度
self.bg_thresh = bg_thresh # 背景RoI的最大重叠度
self.ignore_thresh = ignore_thresh # 忽略is_crowd的真实边界框的阈值
self.use_random = use_random # 是否使用随机采样
self.cascade_iou = cascade_iou # 级联RCNN中的重叠度列表
self.num_classes = num_classes # 类别数
self.assign_on_cpu = assign_on_cpu # 是否在CPU上计算IoU
def __call__(self,
rpn_rois,
rpn_rois_num,
inputs,
stage=0,
is_cascade=False,
add_gt_as_proposals=True):
gt_classes = inputs['gt_class'] # 真实类别
gt_boxes = inputs['gt_bbox'] # 真实边界框
is_crowd = inputs.get('is_crowd', None) # 是否为拥挤场景
# rois, tgt_labels, tgt_bboxes, tgt_gt_inds
# new_rois_num
# 生成RoI的分配目标,包括分配的RoIs、RoI数量和目标标签等信息
outs = generate_proposal_target(
rpn_rois, gt_classes, gt_boxes, self.batch_size_per_im,
self.fg_fraction, self.fg_thresh, self.bg_thresh, self.num_classes,
self.ignore_thresh, is_crowd, self.use_random, is_cascade,
self.cascade_iou[stage], self.assign_on_cpu, add_gt_as_proposals)
rois = outs[0]
rois_num = outs[-1]
# tgt_labels, tgt_bboxes, tgt_gt_inds
targets = outs[1:4]
return rois, rois_num, targets # 返回RoIs、RoI数量和目标标签等信息
它是目标检测中用于将RoIs与真实目标进行匹配和分配目标标签的模块。该模块的主要作用是确定RoIs是前景还是背景,并为RoIs分配类别标签和目标标签,以供模型的训练使用。它还支持级联RCNN等高级目标检测方法的需求。
roi align
roi_extractor 是用于从特征图中提取感兴趣区域(RoIs)的模块。
roi_extractor 的主要功能是从骨干网络(backbone)提取特征图中的感兴趣区域(RoIs)的特征。这些RoIs通常是通过RPN(Region Proposal Network)或其他方法生成的,它们是模型用来进行目标检测的候选区域。
输入参数: 在给定的代码中,roi_extractor 的输入参数包括 body_feats、rois 和 rois_num。具体解释如下:
body_feats(list[Tensor]):特征图列表,是从骨干网络中获得的特征图,通常包含多个尺度的特征图。rois(list[Tensor]):RoIs的坐标信息,通常是由RPN模块生成的,用于指定需要从特征图中提取特征的感兴趣区域。rois_num(Tensor):每张图像中的RoI数量,用于区分不同图像中的RoIs。
RoI特征提取过程: roi_extractor 将根据输入的RoIs,在特征图中提取与这些RoIs相对应的特征。这个过程包括从特征图中截取RoIs区域,将其调整为固定大小,并在每个RoI上执行相应的操作以提取特征。
多尺度支持: roi_extractor 通常支持多尺度的特征提取,因为目标可能在不同的尺度上出现。它能够从不同尺度的特征图中提取RoIs的特征,以增强目标检测模型的性能。
返回值: 该模块的输出通常是RoIs的特征,这些特征将作为后续目标分类和边界框回归任务的输入。在给定代码中,roi_extractor 并没有直接返回特征,而是作为下一层模块的输入,进一步传递给 self.head(rois_feat),并在后续的操作中使用。
Mask Head
MaskHead是目标检测中用于生成掩码(mask)的模块。该模块的主要作用是将RoIs中的对象区域分割出来,生成对象掩码,以便进行实例分割任务。 下面是MaskHead的初始化代码:
@register
class MaskHead(nn.Layer):
__shared__ = ['num_classes', 'export_onnx']
__inject__ = ['mask_assigner']
"""
RCNN mask head(掩码头部)
Args:
head (nn.Layer): 掩码头部中的特征提取模块
roi_extractor (object): RoI提取模块
mask_assigner (object): 掩码分配模块,用于标记和采样掩码
num_classes (int): 类别数
share_bbox_feat (bool): 是否与边界框头部共享特征,默认为False
"""
def __init__(self,
head,
roi_extractor=_get_class_default_kwargs(RoIAlign),
mask_assigner='MaskAssigner',
num_classes=80,
share_bbox_feat=False,
export_onnx=False):
super(MaskHead, self).__init__()
# 初始化MaskHead的属性
self.num_classes = num_classes # 类别数
self.export_onnx = export_onnx # 是否导出ONNX模型
# 初始化RoI提取模块
self.roi_extractor = roi_extractor
if isinstance(roi_extractor, dict):
self.roi_extractor = RoIAlign(**roi_extractor)
# 初始化特征提取模块和特征通道数
self.head = head
self.in_channels = head.out_channels()
# 初始化掩码分配模块和其他属性
self.mask_assigner = mask_assigner
self.share_bbox_feat = share_bbox_feat
self.bbox_head = None
# 创建用于预测掩码的卷积层
self.mask_fcn_logits = nn.Conv2D(
in_channels=self.in_channels,
out_channels=self.num_classes,
kernel_size=1,
weight_attr=paddle.ParamAttr(initializer=KaimingNormal(
fan_in=self.num_classes)))
self.mask_fcn_logits.skip_quant = True
forward_train
def forward_train(self, body_feats, rois, rois_num, inputs, targets,
bbox_feat):
"""
在训练阶段前向传播计算损失。
Args:
body_feats (list[Tensor]): 多级别骨干网络特征的列表
rois (list[Tensor]): 每批次的候选框列表,每个候选框的形状为 [N, 4]
rois_num (Tensor): 每批次的候选框数量的张量
inputs (dict): 包含真实标签信息的字典
Returns:
dict: 包含掩码损失的字典,键为'loss_mask'
"""
# 从目标(targets)中提取目标标签、忽略标签和目标索引
tgt_labels, _, tgt_gt_inds = targets
# 使用掩码分配器(mask_assigner)为RoIs分配掩码标签和采样目标掩码
rois, rois_num, tgt_classes, tgt_masks, mask_index, tgt_weights = self.mask_assigner(
rois, tgt_labels, tgt_gt_inds, inputs)
# 如果共享边界框特征,则从bbox_feat中选择与掩码对应的特征
if self.share_bbox_feat:
rois_feat = paddle.gather(bbox_feat, mask_index)
else:
# 否则,使用RoI提取器从多级别骨干网络特征中提取RoI特征
rois_feat = self.roi_extractor(body_feats, rois, rois_num)
# 通过头部模块提取掩码特征
mask_feat = self.head(rois_feat)
# 使用掩码卷积层生成掩码预测
mask_logits = self.mask_fcn_logits(mask_feat)
# 计算掩码损失
loss_mask = self.get_loss(mask_logits, tgt_classes, tgt_masks,
tgt_weights)
# 返回损失字典,其中包含掩码损失
return {'loss_mask': loss_mask}
forward_test
def forward_test(self,
body_feats,
rois,
rois_num,
scale_factor,
feat_func=None):
"""
在测试阶段前向传播计算掩码预测。
Args:
body_feats (list[Tensor]): 多级别骨干网络特征的列表
rois (Tensor): 边界框头部的预测结果,形状为 [N, 6]
rois_num (Tensor): 每批次的预测数量的张量
scale_factor (Tensor): 原始大小到输入大小的缩放因子
feat_func (callable): 用于处理RoI特征的可调用函数,仅在共享边界框特征时使用
Returns:
Tensor: 预测的掩码,形状为 [N, H, W],其中N是RoIs的数量,H和W是掩码的高度和宽度
"""
if not self.export_onnx and rois.shape[0] == 0:
# 如果没有RoIs,返回形状为 [1, 1, 1] 的全零张量
mask_out = paddle.full([1, 1, 1], -1)
else:
bbox = [rois[:, 2:]] # 提取RoIs的坐标信息
labels = rois[:, 0].cast('int32') # 提取RoIs的类别标签
# 使用RoI提取器从多级别骨干网络特征中提取RoI特征
rois_feat = self.roi_extractor(body_feats, bbox, rois_num)
if self.share_bbox_feat:
assert feat_func is not None
# 如果共享边界框特征,则通过feat_func处理RoI特征
rois_feat = feat_func(rois_feat)
# 通过头部模块提取掩码特征
mask_feat = self.head(rois_feat)
# 使用掩码卷积层生成掩码预测
mask_logit = self.mask_fcn_logits(mask_feat)
if self.num_classes == 1:
# 如果只有一个类别,应用Sigmoid函数并提取掩码的第一个通道
mask_out = F.sigmoid(mask_logit)[:, 0, :, :]
else:
# 如果有多个类别,提取与每个RoI的类别对应的掩码
num_masks = paddle.shape(mask_logit)[0]
index = paddle.arange(num_masks).cast('int32')
mask_out = mask_logit[index, labels]
mask_out_shape = paddle.shape(mask_out)
mask_out = paddle.reshape(mask_out, [
paddle.shape(index), mask_out_shape[-2], mask_out_shape[-1]
])
mask_out = F.sigmoid(mask_out)
return mask_out
mask_assigner
MaskAssigner 的作用是为每个RoI(候选框)分配掩码标签和生成掩码目标。它的主要任务是为掩码分割任务提供标签和目标,以便在训练阶段用于计算掩码损失和优化掩码模型。
以下是关于 MaskAssigner 的详细解释:
num_classes参数表示数据集中的类别数量。这是一个整数,指定了要为多少个不同的对象类别生成掩码。mask_resolution参数表示掩码目标的分辨率,通常用于指定生成的掩码的空间尺寸。默认值为 14,通常用于生成 14x14 像素的掩码。
MaskAssigner 的工作流程包括以下步骤:
选择RoIs标签(候选框的类别标签):根据提供的RoIs和与之关联的目标标签(即目标的类别标签),为每个RoI分配一个类别标签(前景或背景)。这一步决定了每个RoI是前景(需要生成掩码)还是背景(不需要生成掩码)。
编码RoIs和对应的gt多边形(ground-truth polygons):对于被标记为前景的RoIs,将它们与相应的gt多边形进行编码,以生成掩码目标。这一步确定了掩码的形状和内容,以便与预测掩码进行比较并计算损失。
最终,MaskAssigner 返回了一个包含以下信息的输出:
mask_rois:被分配掩码的RoIs列表。mask_rois_num:每个RoI所包含的掩码的数量。tgt_classes:与掩码RoIs相关联的目标类别标签。tgt_masks:生成的掩码目标。mask_index:掩码RoIs在RoIs列表中的索引。tgt_weights:掩码损失的权重。
MaskAssigner 是一个用于生成掩码分割任务所需的标签和目标的模块,它为训练阶段提供了用于计算损失的掩码信息。
下面我们看一下 MaskAssigner 的实现代码:
@register
@serializable
class MaskAssigner(object):
__shared__ = ['num_classes', 'mask_resolution']
"""
掩码目标分配模块
分配过程包括三个步骤:
1. 选择具有前景标签的RoIs。
2. 编码RoIs和相应的gt多边形以生成掩码目标。
Args:
num_classes (int): 类别数量
mask_resolution (int): 掩码目标的分辨率,默认为 14
"""
def __init__(self, num_classes=80, mask_resolution=14):
super(MaskAssigner, self).__init__()
self.num_classes = num_classes # 数据集中的类别数量
self.mask_resolution = mask_resolution # 掩码目标的分辨率
def __call__(self, rois, tgt_labels, tgt_gt_inds, inputs):
# 从输入中获取gt多边形信息
gt_segms = inputs['gt_poly']
# 调用生成掩码目标的函数,传递相关信息并获得输出
outs = generate_mask_target(gt_segms, rois, tgt_labels, tgt_gt_inds,
self.num_classes, self.mask_resolution)
# 返回输出,其中包括掩码RoIs、RoIs数量、目标类别、掩码目标、RoIs索引和目标权重
return outs
其中 generate_mask_target 的实现如下:
def generate_mask_target(gt_segms, rois, labels_int32, sampled_gt_inds,
num_classes, resolution):
"""
生成掩码目标的函数
Args:
gt_segms (List[List[ndarray]]): 每个图像的ground-truth掩码,以列表形式组织
rois (List[Tensor]): 每个图像的RoIs列表,形状为 [N, 4]
labels_int32 (List[Tensor]): 每个图像的目标类别标签列表
sampled_gt_inds (List[Tensor]): 每个图像的已采样的ground-truth索引列表
num_classes (int): 类别数量
resolution (int): 掩码目标的分辨率
Returns:
mask_rois (List[Tensor]): 每个图像的掩码RoIs列表
mask_rois_num (List[Tensor]): 每个图像的掩码RoIs数量列表
tgt_classes (List[Tensor]): 每个图像的掩码目标的类别标签列表
tgt_masks (List[Tensor]): 每个图像的掩码目标列表
mask_index (List[Tensor]): 每个图像的掩码RoIs的索引列表
tgt_weights (List[Tensor]): 每个图像的掩码目标的权重列表
"""
mask_rois = [] # 用于存储每个图像的掩码RoIs
mask_rois_num = [] # 用于存储每个图像的掩码RoIs数量
tgt_masks = [] # 用于存储每个图像的掩码目标
tgt_classes = [] # 用于存储每个图像的掩码目标的类别标签
mask_index = [] # 用于存储每个图像的掩码RoIs的索引
tgt_weights = [] # 用于存储每个图像的掩码目标的权重
for k in range(len(rois)):
labels_per_im = labels_int32[k]
# 选择标签为前景的RoIs
fg_inds = paddle.nonzero(
paddle.logical_and(labels_per_im != -1, labels_per_im !=
num_classes))
has_fg = True
# 如果前景为空,生成虚拟RoI
if fg_inds.numel() == 0:
has_fg = False
fg_inds = paddle.ones([1, 1], dtype='int64')
inds_per_im = sampled_gt_inds[k]
inds_per_im = paddle.gather(inds_per_im, fg_inds)
rois_per_im = rois[k]
fg_rois = paddle.gather(rois_per_im, fg_inds)
# 将前景RoI复制到CPU以生成ground-truth掩码
boxes = fg_rois.numpy()
gt_segms_per_im = gt_segms[k]
new_segm = []
inds_per_im = inds_per_im.numpy()
# 获取与前景RoIs关联的ground-truth多边形
if len(gt_segms_per_im) > 0:
for i in inds_per_im:
new_segm.append(gt_segms_per_im[i])
fg_inds_new = fg_inds.reshape([-1]).numpy()
results = []
# 使用ground-truth多边形生成RoI内的掩码
if len(gt_segms_per_im) > 0:
for j in range(fg_inds_new.shape[0]):
results.append(
rasterize_polygons_within_box(new_segm[j], boxes[j],
resolution))
else:
results.append(paddle.ones([resolution, resolution], dtype='int32'))
fg_classes = paddle.gather(labels_per_im, fg_inds)
weight = paddle.ones([fg_rois.shape[0]], dtype='float32')
if not has_fg:
# 如果前景为空,则所有采样的类别都是背景,将其权重设为0
fg_classes = paddle.zeros([1], dtype='int32')
weight = weight - 1
tgt_mask = paddle.stack(results)
tgt_mask.stop_gradient = True
fg_rois.stop_gradient = True
mask_index.append(fg_inds)
mask_rois.append(fg_rois)
mask_rois_num.append(paddle.shape(fg_rois)[0:1])
tgt_classes.append(fg_classes)
tgt_masks.append(tgt_mask)
tgt_weights.append(weight)
# 将各个图像的信息合并为一个列表
mask_index = paddle.concat(mask_index)
mask_rois_num = paddle.concat(mask_rois_num)
tgt_classes = paddle.concat(tgt_classes, axis=0)
tgt_masks = paddle.concat(tgt_masks, axis=0)
tgt_weights = paddle.concat(tgt_weights, axis=0)
return mask_rois, mask_rois_num, tgt_classes, tgt_masks, mask_index, tgt_weights