异构计算与CUDA
异构计算与CUDA
异构计算
异构计算 “Heterogeneous Computing” 是一种特殊的并行分布式计算系统。它能够经济有效地实现高计算能力,可扩展性强,能够非常高效地利用计算资源。与之相对的概念就是同构计算“Homogeneous Computing”,也就是为大家熟知的多核理念。为了突破计算算力受制于功耗的瓶颈,多核CPU技术得到越来越多的应用。强大的CPU采用越来越多的CPU内核这就是传统同构计算系统。很快人们就发现在AI人工智能和自动驾驶爆炸式增长的计算需求下,传统同构计算系统已经无法满足要求,GPU、DSP、FPGA和ASIC由于特定需求下高效性越来越多的被应用。
x86 CPU+GPU的这种异构应该是最常见的,也有CPU+FPGA,CPU+DSP等各种各样的组合,CPU+GPU在每个笔记本或者台式机上都能找到。当然超级计算机大部分也采用异构计算的方式来提高吞吐量。
异构架构虽然比传统的同构架构运算量更大,但是其应用复杂度更高,因为要在两个设备上进行计算,控制,传输,这些都需要人为干预,而同构的架构下,硬件部分自己完成控制,不需要人为设计。
tip
异构计算是指在一个系统中,使用多种不同的处理器和协处理器,以解决一个计算问题。异构计算的目的是利用每种处理器的优势,以提高整个系统的性能。
异构架构
一句话概括:异构计算是指在一个系统中,使用多种不同的处理器和协处理器,以解决一个计算问题。异构计算的目的是利用每种处理器的优势,以提高整个系统的性能。
举一个例子,我们在做深度学习的时候,通常会使用CPU和GPU两种处理器。CPU的优势是可以处理各种各样的任务,而GPU的优势是可以高效地进行并行计算。因此,我们可以将CPU用于控制流程,将GPU用于数据流程,以提高整个系统的性能。一台 intel i7-4790 CPU加上两台Titan x GPU构成的工作站,GPU插在主板的PCIe卡口上,运行程序的时候,CPU像是一个控制者,指挥两台Titan完成工作后进行汇总,和下一步工作安排,所以CPU我们可以把它看做一个指挥者,主机端,host,而完成大量计算的GPU是我们的计算设备,device。
引用 [2] 里面的图片和表述,如下图所示:
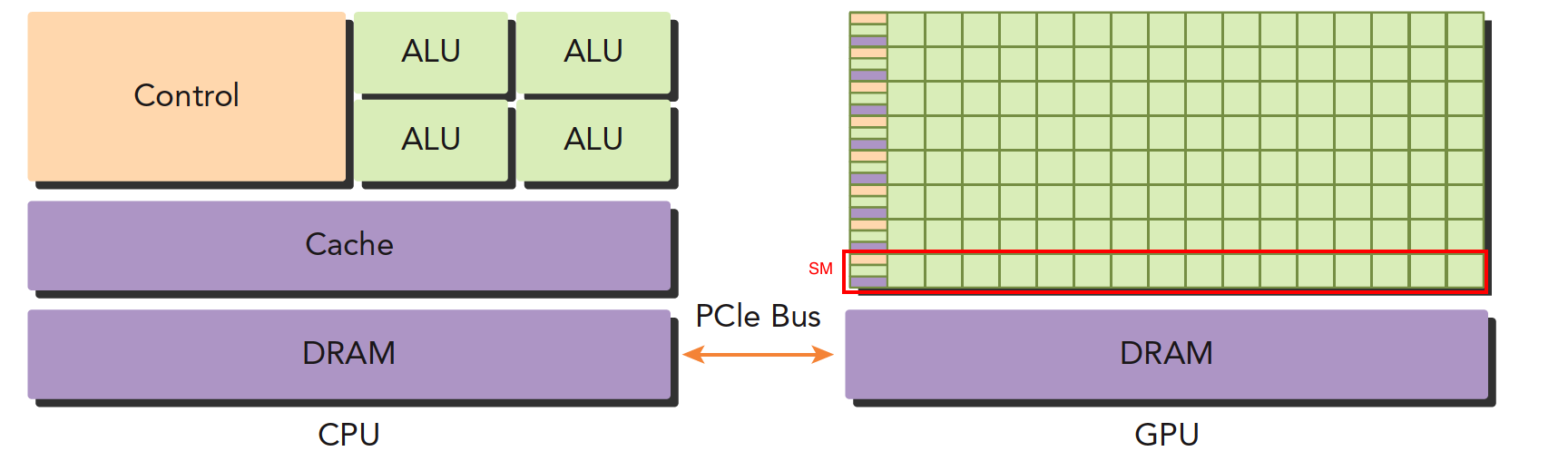
上面这张图能大致反应CPU和GPU的架构不同。
- 左图:一个四核CPU一般有四个ALU,ALU是完成逻辑计算的核心,也是我们平时说四核八核的核,控制单元,缓存也在片上,DRAM是内存,一般不在片上,CPU通过总线访问内存。
- 右图:GPU,绿色小方块是ALU,我们注意红色框内的部分SM,这一组ALU公用一个Control单元和Cache,这个部分相当于一个完整的多核CPU,但是不同的是ALU多了,control部分变小,可见计算能力提升了,控制能力减弱了,所以对于控制(逻辑)复杂的程序,一个GPU的SM是没办法和CPU比较的,但是对了逻辑简单,数据量大的任务,GPU更高效。
tip
CPU和GPU之间通过PCIe总线连接,用于传递指令和数据,CPU和GPU之间的数据传输是一个很大的瓶颈,所以我们在编程的时候,要尽量减少CPU和GPU之间的数据传输。
一个异构应用包含两种以上架构,所以代码也包括不止一部分:
- 主机端代码:运行在CPU上,负责控制整个程序的流程,比如读取数据,将数据传输到GPU,将GPU计算的结果传输回CPU,将结果写入硬盘等等。
- 设备端代码:运行在GPU上,负责完成大量的计算任务。
CUDA
CUDA是异构计算的一种实现方式,是NVIDIA推出的异构计算平台和编程模型。 本来一开始GPU之前是不可编程的或者说是专用的,只能用来做图形处理,后来NVIDIA推出了CUDA,使得GPU可以用来做通用计算,这样就可以利用GPU的高并行性来加速计算了。
CUDA平台不是单单指软件或者硬件,而是建立在Nvidia GPU上的一整套平台,并扩展出多语言支持。
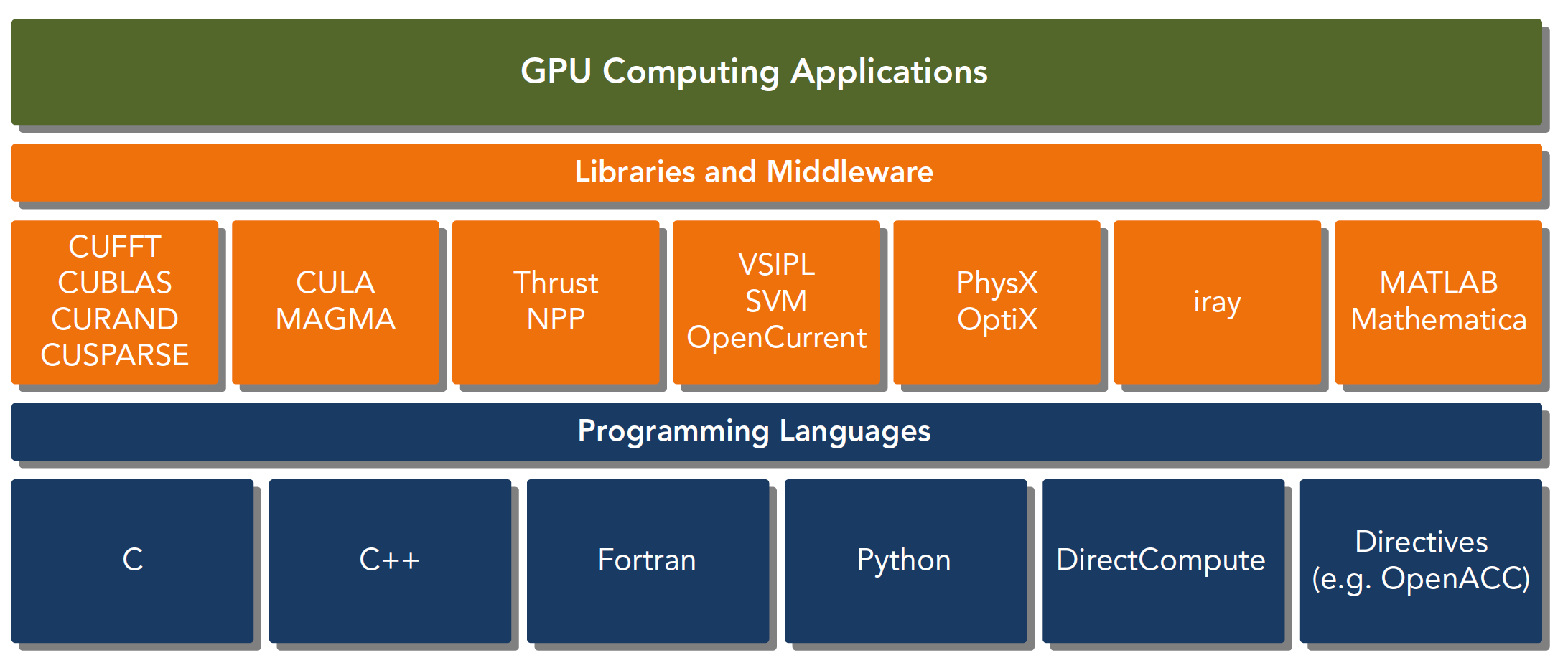
如图所示,CUDA平台包括:
- CUDA架构:包括GPU硬件架构和CUDA指令集架构。
- CUDA工具链:包括CUDA C/C++编译器,CUDA-GDB调试器,CUDA Profiler等。
- CUDA运行时:包括CUDA驱动程序和CUDA运行时库,用于在GPU上执行CUDA程序。
- CUDA编程语言:包括CUDA C/C++和CUDA Fortran,用于在GPU上编写CUDA程序。
CUDA API
CUDA API是CUDA的编程接口,包括CUDA Runtime API和CUDA Driver API。
- CUDA Runtime API:是一组运行时函数,用于在CUDA程序中调用GPU的硬件资源。
- CUDA Driver API:是一组底层函数,用于在CUDA程序中调用GPU的硬件资源。
驱动API是低级的API,使用相对困难,运行时API是高级API使用简单,其实现基于驱动API。
这两种API是互斥的,也就是你只能用一个,两者之间的函数不可以混合调用,只能用其中的一个库。
一个CUDA应用通常可以分解为两部分:
- CPU 主机端代码
- GPU 设备端代码
在编译的时候,CPU代码和GPU代码分别编译。主机端代码通过CPU编译器编译,设备端代码(核函数)使用nvcc编译器编译。
tip
核函数是我们后面主要接触的一段代码,就是设备上执行的程序段
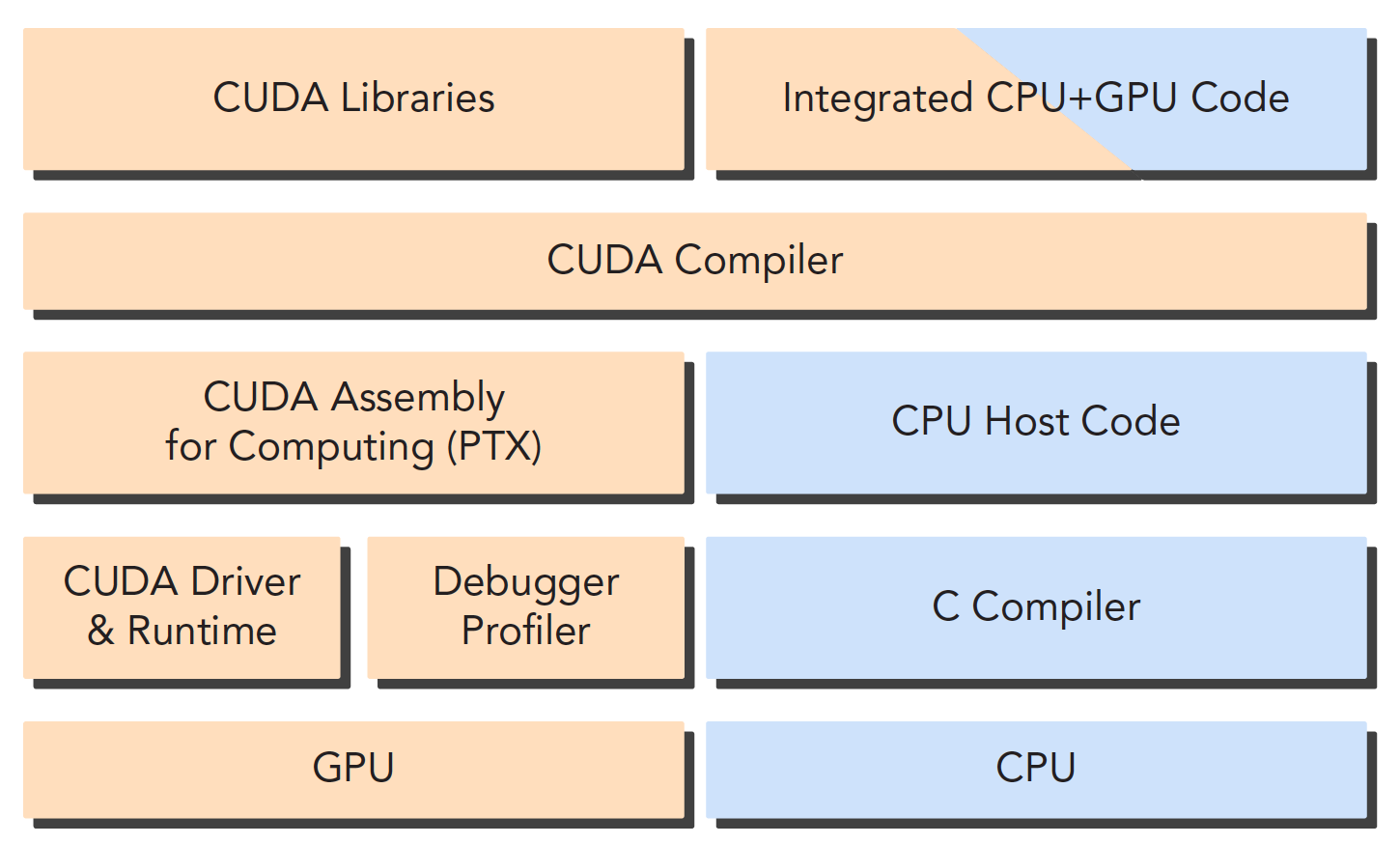
上面我们提到GPU设备端代码是使用nvcc编译器编译的,那么nvcc是什么呢?
nvcc是NVIDIA CUDA Compiler的缩写,是NVIDIA CUDA编译器,是一种支持CUDA C/C++的编译器,可以将CUDA C/C++代码编译为PTX(Parallel Thread Execution)代码,PTX是一种中间代码,可以在不同的GPU上运行,也可以编译为不同的机器码,这样就可以在不同的GPU上运行了。
编译的过程如下图所示:
Hello World
下面我们来看一个CUDA的Hello World程序,代码如下:
#include <stdio.h>
__global__ void helloFromGPU()
{
printf("Hello World from GPU!\n");
}
int main()
{
printf("Hello World from CPU!\n");
helloFromGPU<<<1, 10>>>();
cudaDeviceReset();
return 0;
}
上面的代码中,我们定义了一个核函数helloFromGPU,然后在主函数中调用了这个核函数。
核函数是在GPU上执行的,所以我们需要使用__global__关键字来修饰核函数,这样编译器就知道这个函数是在GPU上执行的。
<<<1, 10>>>是核函数的调用语法,第一个参数1表示启动一个线程块,第二个参数10表示每个线程块包含10个线程。
在主函数中,我们先输出了一句话,然后调用了核函数,最后调用了cudaDeviceReset()函数,这个函数用于重置当前设备上的所有资源,这个函数是可选的,但是如果不调用这个函数,那么程序会在退出的时候报错。因为这句话包含了隐式同步,GPU和CPU执行程序是异步的,核函数调用后成立刻会到主机线程继续,而不管GPU端核函数是否执行完毕,所以上面的程序就是GPU刚开始执行,CPU已经退出程序了,所以我们要等GPU执行完了,再退出主机线程。
CUDA 程序流程
一般一个CUDA程序的流程如下:
- 分配GPU内存
- 拷贝内存到设备
- 调用CUDA内核函数来执行计算
- 把计算完成数据拷贝回主机端
- 内存销毁
下面我们来看一个简单的例子,代码如下:
#include <stdio.h>
__global__ void add(int a, int b, int *c)
{
*c = a + b;
}
int main()
{
int c; // host copy of c
int *dev_c; // device copy of c
cudaMalloc((void**)&dev_c, sizeof(int)); // allocate space for dev_c
add<<<1, 1>>>(2, 7, dev_c); // call add() kernel on GPU
// copy result back from GPU to CPU
cudaMemcpy(&c, dev_c, sizeof(int), cudaMemcpyDeviceToHost);
// print result
printf("2 + 7 = %d\n", c);
// free memory on GPU
cudaFree(dev_c);
return 0;
}
上面的代码中,我们定义了一个核函数add,然后在主函数中调用了这个核函数。
在主函数中,我们先定义了一个变量c,然后定义了一个指针dev_c,这个指针指向GPU上的内存,然后我们调用了cudaMalloc函数来分配GPU内存,这个函数的第一个参数是一个指针,指向GPU上的内存,第二个参数是分配的内存大小。
然后我们调用了核函数add,这个函数的第一个参数是2,第二个参数是7,第三个参数是指向GPU上内存的指针dev_c。
然后我们调用了cudaMemcpy函数,这个函数用于把GPU上的内存拷贝到主机端,这个函数的第一个参数是主机端的指针,第二个参数是GPU端的指针,第三个参数是拷贝的内存大小,第四个参数是拷贝的方向,这里是从GPU拷贝到主机端。
最后我们调用了cudaFree函数,这个函数用于释放GPU上的内存,这个函数的参数是GPU上的指针。
学习CUDA C代码中会遇到的Boss
CPU与GPU的编程主要区别在于对GPU架构的熟悉程度,理解机器的结构是对编程效率影响非常大的一部分,了解你的机器,才能写出更优美的代码,而目前计算设备的架构决定了局部性将会严重影响效率。
CUDA中内存层次结构和线程层次结构是决定性能的两个重要因素。在后续的研究中,CUDA C写核函数的时候我们只写一小段串行代码,但是这段代码被成千上万的线程执行,所有线程执行的代码都是相同的,CUDA编程模型提供了一个层次化的组织线程,直接影响GPU上的执行顺序。
CUDA是如何抽象硬件实现的,这里面又包含了很多的知识,比如线程组的层次结构、内存的层次结构、障碍同步等等。
这些都是我们后面要研究的。除了这些,NVIDIA还提供了很多的工具,比如Nvidia Nsight、CUDA-GDB等等,这些工具可以帮助我们分析CUDA程序的性能,这些工具也是我们后面要学习的。
总结
本文主要介绍了CUDA的基本概念,包括异构计算、CUDA程序的流程,并且概括了我们的将要遇到的苦难和使用到的工具。
tip
大佬说,当我们学会的CUDA,那么编写高效异构计算就会像我们写串行程序一样流畅。希望我也能够达到这个境界。
Reference
[1][如何用通俗易懂的话解释异构计算?](https://www.zhihu.com/question/63207620)
[2][【CUDA 基础】1.1 异构计算与CUDA](https://face2ai.com/CUDA-F-1-1-异构计算-CUDA/)