爬虫猫眼电影
网页URL分析
首先我们打开猫眼电影,进到榜单这一页

我们可以发现它的url是这样的https://maoyan.com/board/4?offset=0
通过分析我们可以知道/board表示榜单,offset表示页数。进入到第二页发现offset变为20,由此可以发现offset的规律
分析网页html并编写正则项
接下来我们右击打开网页源代码,ctrl+a ctrl + c 复制到vscode中打开,右击代码格式化我们就可以得到整整齐齐的的网页源代码喽!
对网页源代码进行分析发现一个网页的信息是包含在一个<dd></dd>里的
<dd>
<i class="board-index board-index-3">3</i>
<a href="/films/4055" title="这个杀手不太冷" class="image-link" data-act="boarditem-click"
data-val="{movieId:4055}">
<img src="//s3plus.meituan.net/v1/mss_e2821d7f0cfe4ac1bf9202ecf9590e67/cdn-prod/file:5788b470/imag
alt="" class="poster-default" />
<img data-src="https://p1.meituan.net/movie/6bea9af4524dfbd0b668eaa7e187c3df767253.jpg@160w_220h_1
alt="这个杀手不太冷" class="board-img" />
</a>
<div class="board-item-main">
<div class="board-item-content">
<div class="movie-item-info">
<p class="name"><a href="/films/4055" title="这个杀手不太冷" data-act="boarditem-click"
data-val="{movieId:4055}">这个杀手不太冷</a></p>
<p class="star">
主演:让·雷诺,加里·奥德曼,娜塔莉·波特曼
</p>
<p class="releasetime">上映时间:1994-09-14(法国)</p>
</div>
<div class="movie-item-number score-num">
<p class="score"><i class="integer">9.</i><i class="fraction">5</i></p>
</div>
</div>
</div>
</dd>
在里面可以发现我们需要的排名,电影名,主演,上映时间
所以我们可以写出我们的正则,这个我写的正则也不是唯一的和我的有一定的差距都可以
'<dd>.*?board-index-(.*?)".*?<img data-src=.*?alt="(.*?)".*?<p class="star">(.*?)</p>.*?"releasetime">(.*?)</p>.*?</dd>'
主要的思路就算把我们要的东西分组出来就ok了
csv文件
将爬取下来的内容保存到csv文件中就ok啦
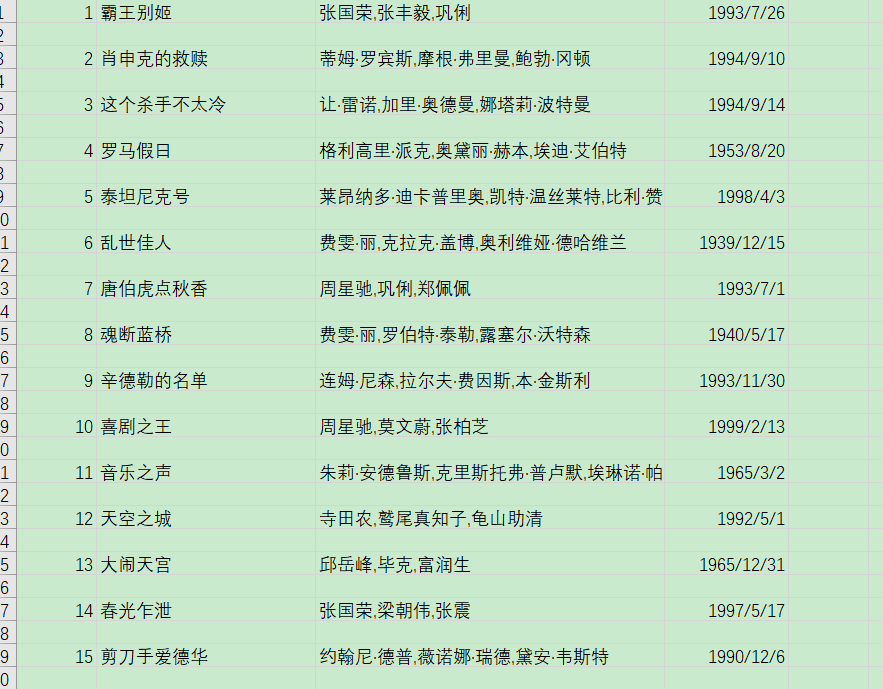
代码
废话就不多说了,下面上代码,代码写了注释,应该可以看懂,还是比较简单的
from urllib import request
import re, time, random, csv
from fake_useragent import UserAgent
class MaoyanSpider:
def __init__(self):
self.url = 'http://maoyan.com/board/4?offset={}'
def get_url(self, offset):
"""
获取url
"""
return self.url.format(offset)
def get_headers(self):
"""
获取伪造的User-Agent
"""
ua = UserAgent()
return {'User-Agent': ua.random}
def get_html(self, headers, offset):
"""
获取html信息
"""
url = self.get_url(offset)
print(url)
res = request.Request(url, headers=headers)
req = request.urlopen(res)
html = req.read().decode()
return html
def pattern_html(self, html):
"""
获取正则匹配的内容
"""
pattern = re.compile(
'<dd>.*?board-index-(.*?)".*?<img data-src=.*?alt="(.*?)".*?<p class="star">(.*?)</p>.*?"releasetime">(.*?)</p>.*?</dd>',
re.S)
return pattern.findall(html)
def save_csv(self, moives):
"""
讲内容保存到csv中
"""
L = []
with open('mouyan.csv', 'a') as f:
writer = csv.writer(f)
for r in moives:
ranking = r[0].strip()
name = r[1].strip()
star = r[2].strip()[3:]
time = r[3].strip()[5:15]
L.append((ranking, name, star, time))
print(ranking, name, time, star)
# 在for循环外面
writer.writerows(L)
# 主运行函数
def run(self):
for i in range(1, 11):
offset = (i - 1) * 10
headers = self.get_headers()
html = self.get_html(headers, offset)
movies = self.pattern_html(html)
self.save_csv(movies)
time.sleep(random.randint(9,13))
if __name__ == '__main__':
maoyan = MaoyanSpider()
maoyan.run()