小米应用商店爬虫(多线程)
多线程介绍
应用场景
1、多进程 :CPU密集程序
2、多线程 :爬虫(网络I/O)、本地磁盘I/O
队列
# 导入模块
from queue import Queue
# 使用
q = Queue()
q.put(url)
q.get() # 当队列为空时,阻塞
q.empty() # 判断队列是否为空,True/False
线程模块
# 导入模块
from threading import Thread
# 使用流程
t = Thread(target=函数名) # 创建线程对象
t.start() # 创建并启动线程
t.join() # 阻塞等待回收线程
爬虫小米应用商店
爬取目标:爬取旁栏中的地址,并且同时爬取地址中对应的app名称以及每个app对应的url链接:
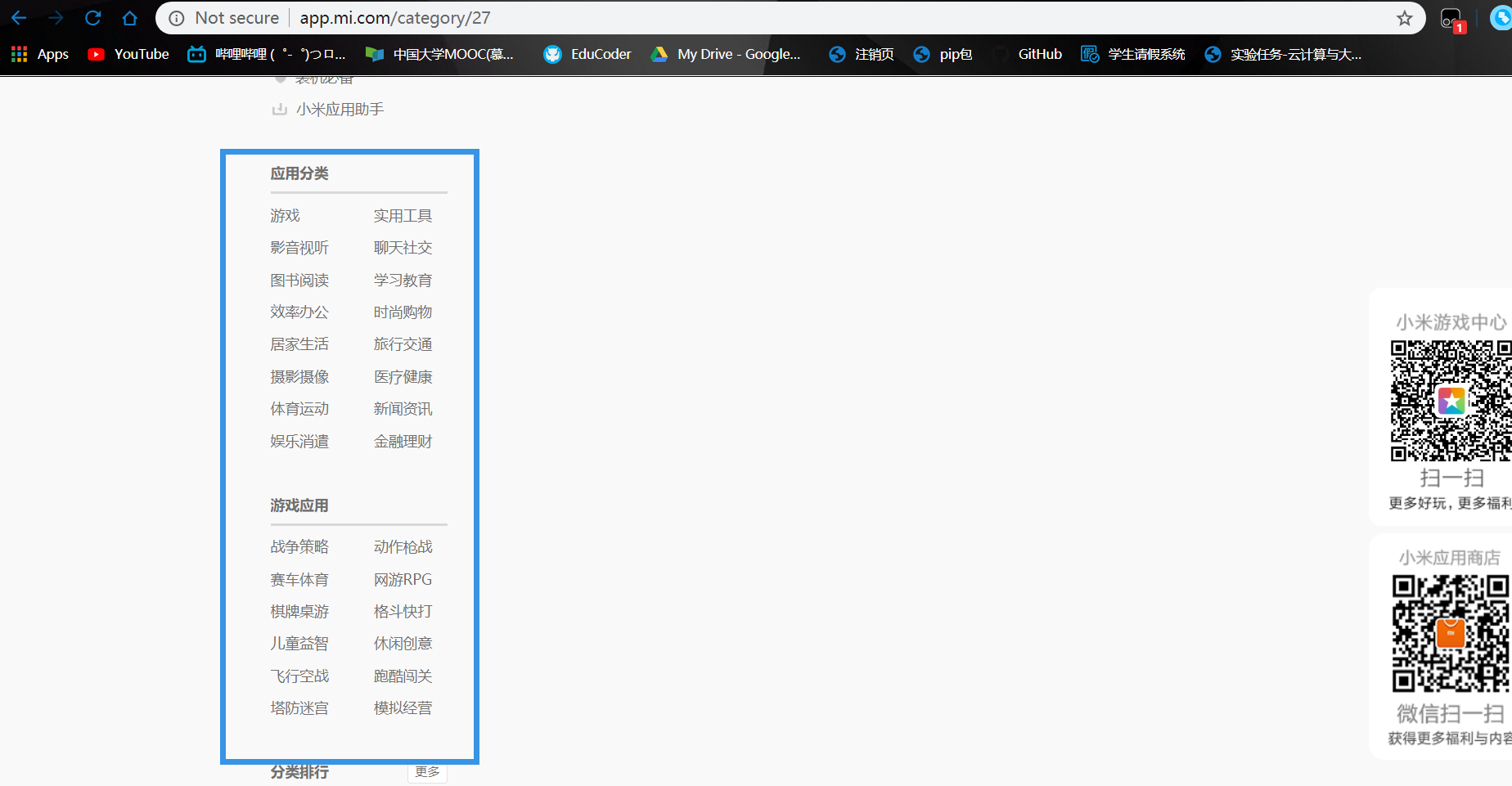
想爬取旁中的url地址
tip
步骤: 右键打开网页源代码,搜索需要的内容 发现是静态页面 使用xpath匹配去匹配需要的内容
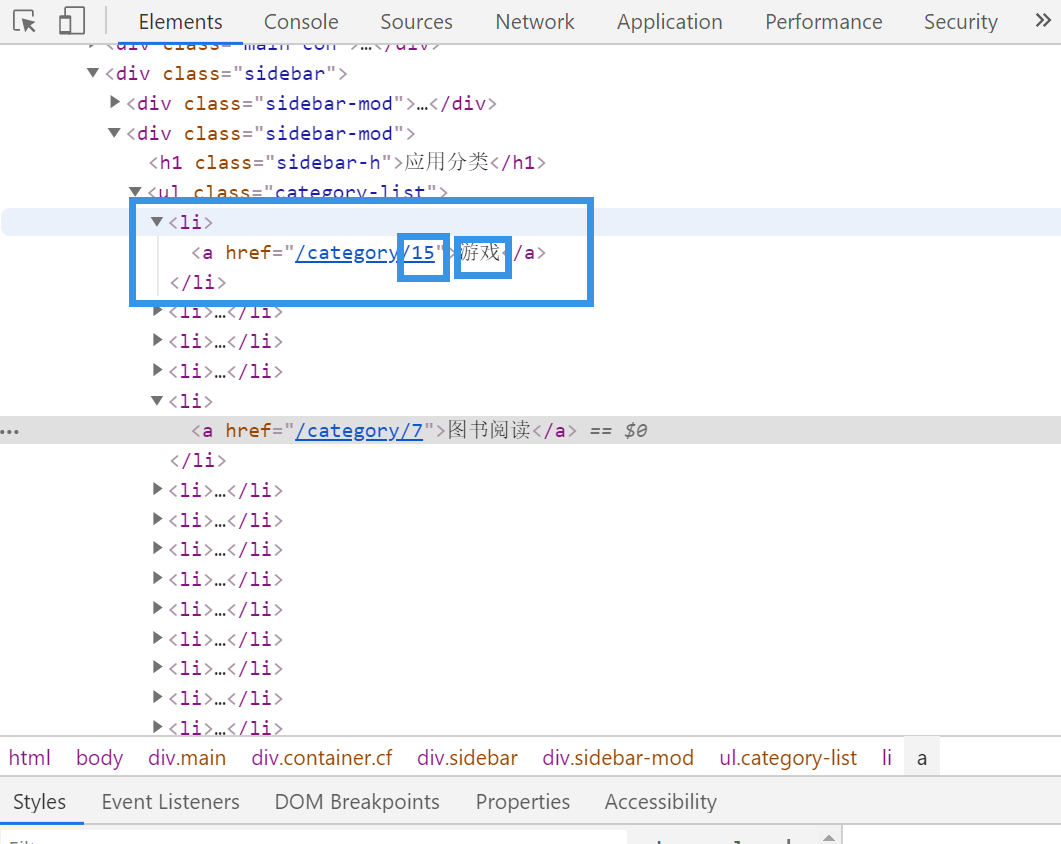
静态的url界面还是非常简单的,可以看到url地址和名称
应用名称://ul[@class="category-list"]/li/a/text()
对应url: //ul[@class="category-list"]/li/a/@href (这里并不是完整的url,但是问题不大后面讲怎么用)
爬虫对应专栏的app名称
1. 确认是否为动态加载
1、页面局部刷新
2、右键查看网页源代码,搜索关键字未搜到
==> 此网站为动态加载网站,需要抓取网络数据包分析
2. F12抓取网络数据包
什么按一下页面的按钮,就抓到一个包,获取方式为get,检查条件有page,categoryld pageSize
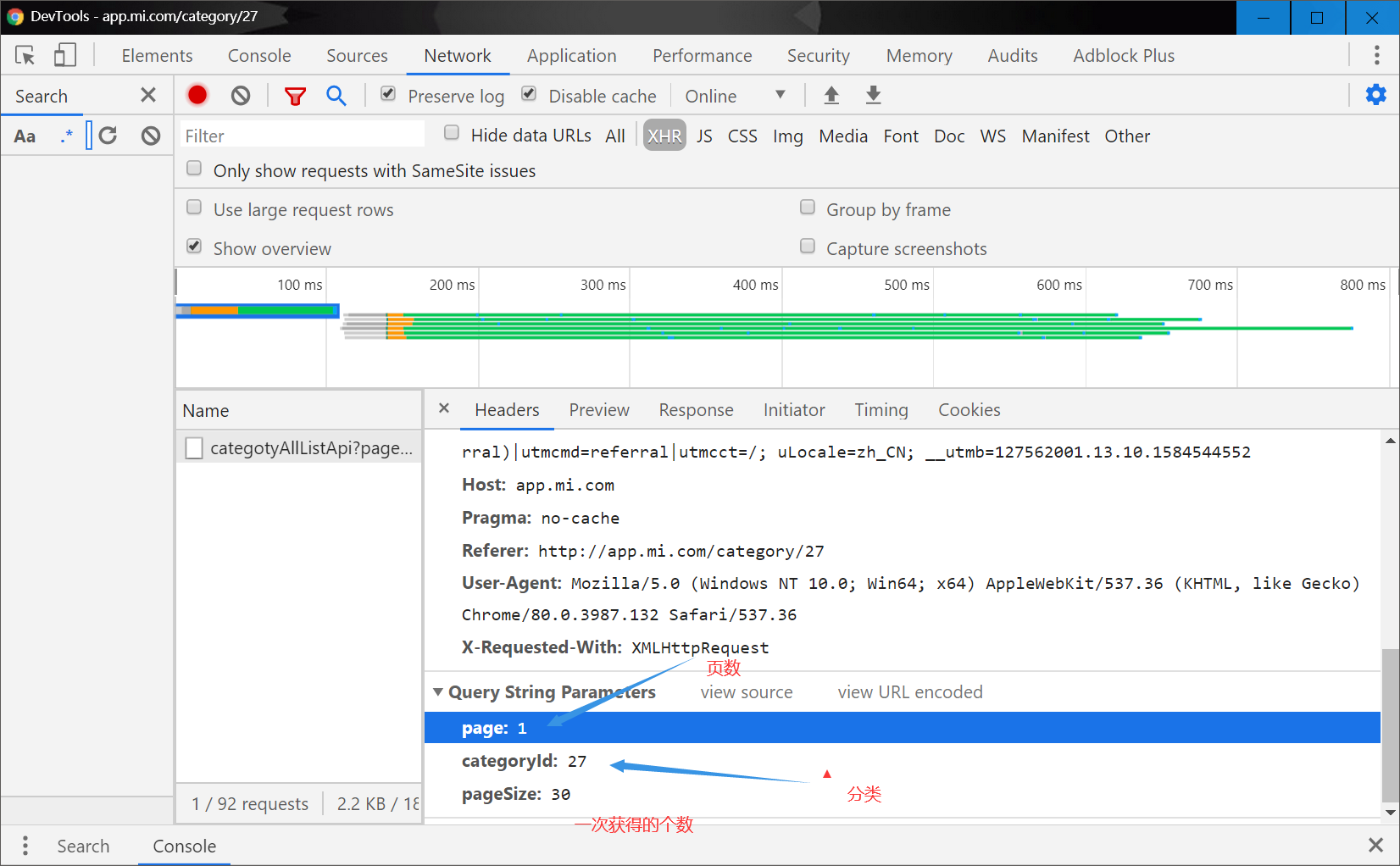
到他请求的地址去看一看
http://app.mi.com/categotyAllListApi?page=1&categoryId=27&pageSize=30
发现是对应的json数据

接下来我们分析一下他的url

获取页数
知道url的类型后我们就知道怎么办了,类别在上面已经获取过了还记得吗?关键这个page怎么获得啊?
观察上面的json数据,我可以看到有一个count的参数,这个参数应该就是这个类别的总的app个数 max_page = count // 30 + 1 这样我们就获得页数啦
思路分析图:
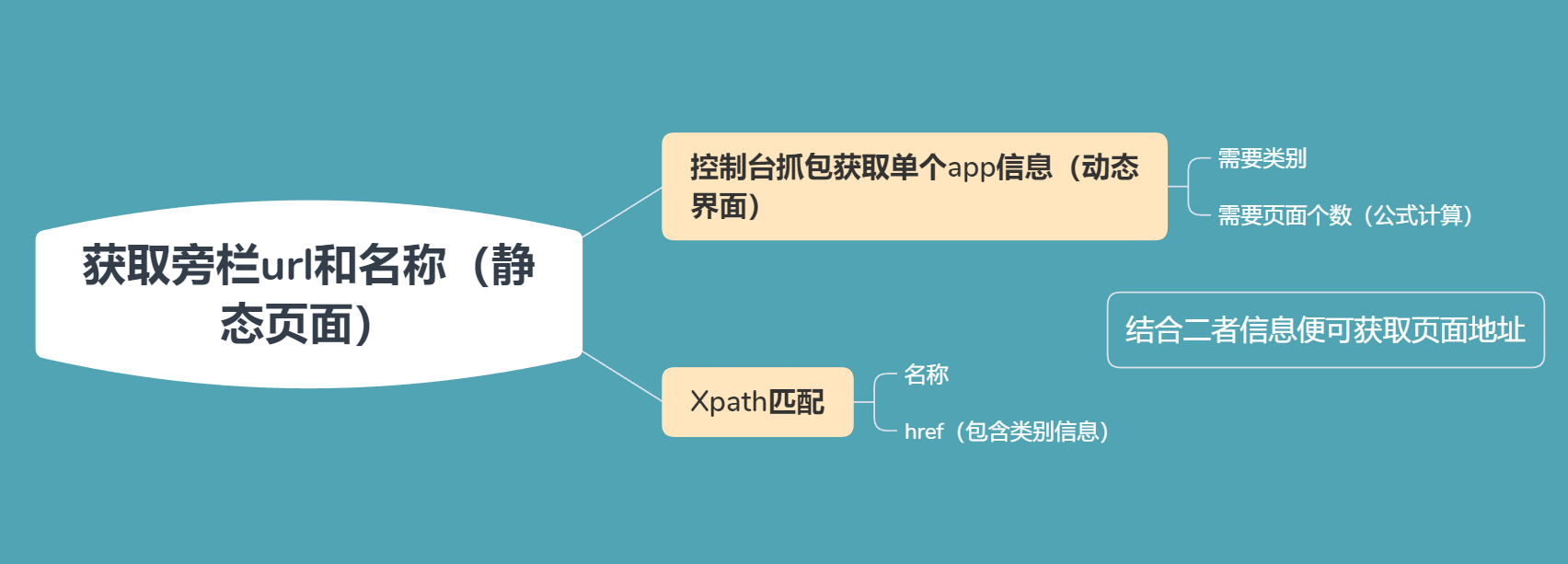
明白思路后就可以去敲代码了
代码
大晚上的小米应用商店应该也没啥人,我就每怎么啥time.sleep, 快点爬完我要去sleep了
import time
import requests
import csv
from queue import Queue
from multiprocessing import Process,Lock
from fake_useragent import UserAgent
from lxml import etree
class XiaoMiSpider:
def __init__(self):
self.q = Queue()
self.url = 'http://app.mi.com/categotyAllListApi?page={}&categoryId={}&pageSize=30'
# 创建url队列,存放所有待爬取的URL地址
self.q = Queue()
# 创建csv文件对象
self.f = open('xiaomi.csv','a')
self.lock = Lock()
self.writer = csv.writer(self.f)
# 计数
self.i = 1
def get_all_type(self):
"""
获取所有的类别信息
"""
url = 'http://app.mi.com/'
html = requests.get(url=url,headers=self.get_headers()).text
html = etree.HTML(html)
categorylds = html.xpath('//ul[@class="category-list"]/li/a/@href')
for categoryld in categorylds:
categoryld = categoryld.split('/')[-1]
self.url_in(categoryld)
def url_in(self,categoryld):
"""
将url推送到队列当中
"""
total = self.get_total(categoryld)
for page in range(total):
url = self.get_url(page,categoryld)
print(url)
self.q.put(url)
def get_url(self,page,categoryId):
url = self.url.format(page,categoryId)
return url
def get_total(self,categoryId):
"""
获取文章的总数
"""
url = self.url.format(0,categoryId)
html = requests.get(url=url,headers=self.get_headers()).json()
count = html['count']
if count % 30 == 0:
total = count // 30
else:
total = (count // 30) + 1
return total
def get_headers(self):
"""
获取请求头
"""
ua = UserAgent()
headers = {'User-Agent':ua.random}
return headers
def parse_html(self):
"""
解析html,并写入csv文件
"""
while True:
if not self.q.empty():
url = self.q.get()
html = requests.get(url,self.get_headers()).json()
app_list = []
for app in html['data']:
name = app['displayName']
print(name)
icon = app['icon']
app_list.append((name,icon))
self.lock.acquire()
self.i += 1
self.lock.release()
# 加锁+释放锁
self.lock.acquire()
self.writer.writerows(app_list)
self.lock.release()
time.sleep(0.1)
else:
break
def run(self):
"""
多线程路口
"""
self.get_all_type()
t_list = []
for i in range(10):
t = Process(target=self.parse_html)
t_list.append(t)
t.start()
for j in t_list:
j.join()
if __name__ == '__main__':
aaa = XiaoMiSpider()
aaa.run()