URL 地址编码
为什么要进行编码?
在百度中搜索:b 站你可以看到上方的 url 是这样的
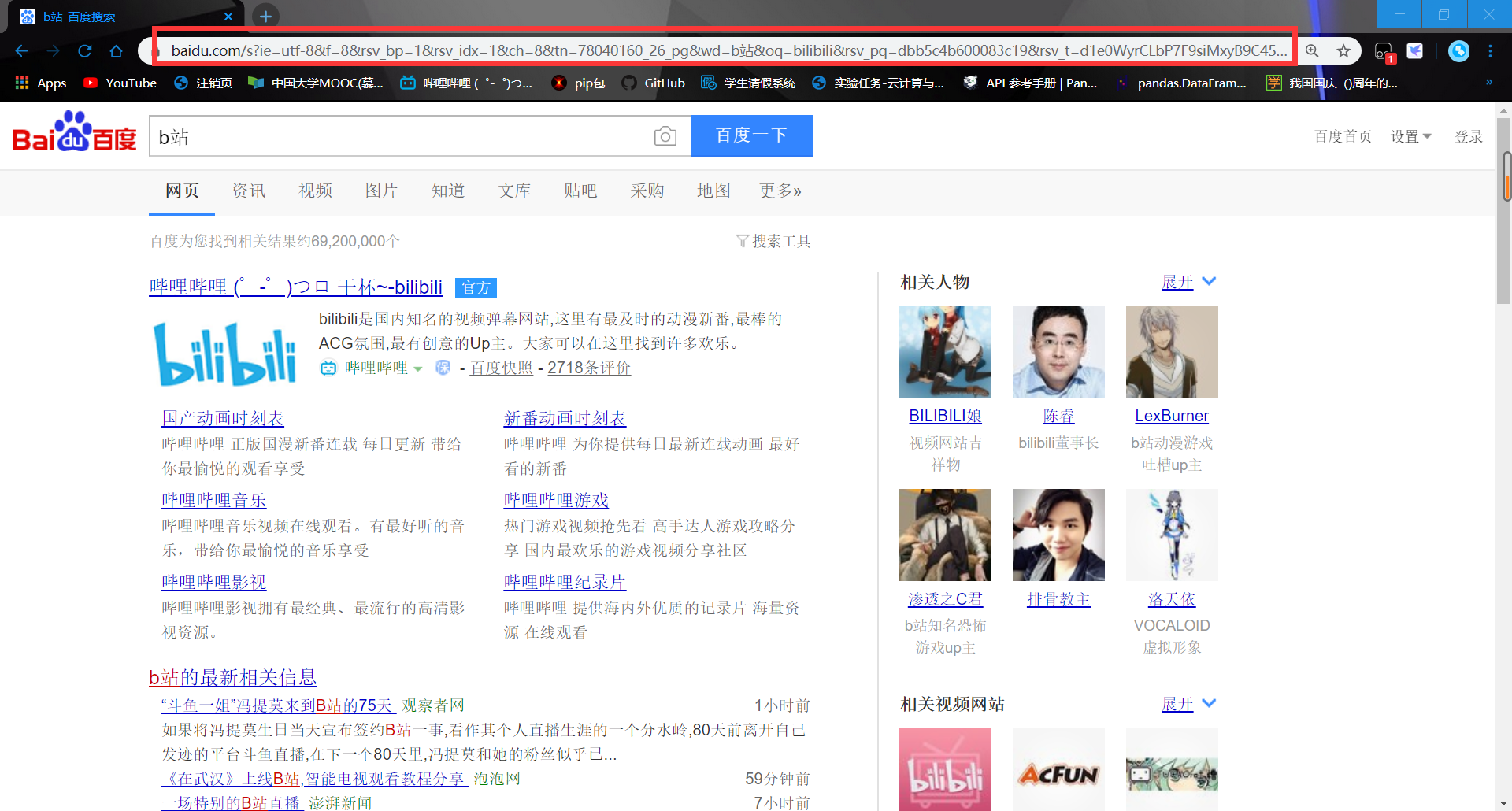
可以看到bai.com/s?之后还有很多以&相连的东西,大部分是我们用不到打,但是可以看到一个wd=b站
把其他的东西删去只留下https://www.baidu.com/s?wd=b站还是可以正常访问的。但是如果你去复制的话得到的是https://www.baidu.com/s?wd=b%E7%AB%99可以知道 url 是不支持中文的会对其进行编码,你在网页可以看到只是因为浏览器给你解码了。
当我们需要获取百度搜索的 b 站的内容时就需要对我们的 url 也进行编码了
URL 地址编码模块
模块名及导入
- 模块
# 模块名
urllib.parse
# 导入
import urllib.parse
from urllib import parse
- 作用
给 URL 地址中查询参数进行编码
编码前:https://www.baidu.com/s?wd=美女
编码后:https://www.baidu.com/s?wd=%E7%BE%8E%E5%A5%B3
常用方法
urllib.parse.urlencode({dict})
- URL 地址中一个查询参数
# 查询参数:{'wd' : '美女'}
# urlencode编码后:'wd=%e7%be%8e%e5%a5%b3'
# 示例代码
query_string = {'wd' : '美女'}
result = urllib.parse.urlencode(query_string)
# result: 'wd=%e7%be%8e%e5%a5%b3'
- URL 地址中多个查询参数
from urllib import parse
params = {
'wd' : '美女',
'pn' : '50'
}
params = parse.urlencode(query_string_dict)
url = 'http://www.baidu.com/s?{}'.format(params)
print(url)
- 拼接 URL 地址的 3 种方式
# 1、字符串相加
baseurl = 'http://www.baidu.com/s?'
params = 'wd=%E7XXXX&pn=20'
url = baseurl + params
# 2、字符串格式化(占位符)
params = 'wd=%E7XXXX&pn=20'
url = 'http://www.baidu.com/s?%s'% params
# 3、format()方法
url = 'http://www.baidu.com/s?{}'
params = 'wd=#E7XXXX&pn=20'
url = url.format(params)
- 练习
在 360 中输入要搜索的内容,把响应内容保存到本地文件
这年头,百度搜索和 bing 搜索这种简单的小爬虫都用不了了,无奈欺负欺负 360 搜索吧
from urllib import parse
from urllib import request
def get_url(word):
baseurl = 'https://www.so.com/s?'
parses = {'q': word}
parses = parse.urlencode(parses)
url = baseurl + parses
return url
def write_html(url, word):
print(url)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'}
req = request.Request(url, headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
filepath = word + '.html'
with open(filepath, 'w',encoding='utf-8') as f:
f.write(html)
if __name__ == '__main__':
word = input('请输入你想搜索的内容: ')
url = get_url(word)
write_html(url,word)