NF 综述论文 标准化流的定义和基础 我们的目标是使用简单的概率分布来建立我们想要的更为复杂更有表达能力的概率分布,使用的方法就是Normalizing Flow,flow的字面意思是一长串的 T T T T T T
Normalizing Flow’s properties 假设有一变量 u \mathbf{u} u u ∼ p u ( u ) \mathbf{u} \sim p_u(\mathbf{u}) u ∼ p u ( u ) T , x = T ( u ) , p u ( u ) T, \mathbf{x}=T(\mathbf{u}), p_u(\mathbf{u}) T , x = T ( u ) , p u ( u ) T T T T T T T − 1 T^{-1} T − 1 x \mathbf{x} x u \mathbf{u} u
1、x \mathbf{x} x u \mathbf{u} u T T T
2、变换 T T T T T T T T T
3、变换 T T T T i T_i T i
从使用角度来说,一个flow-based model提供了两个操作,一是sampling,即从分布 p u ( u ) p_u(\mathbf{u}) p u ( u ) u \mathbf{u} u u \mathbf{u} u x \mathbf{x} x x = T ( u ) \mathbf{x}=T(\mathbf{u}) x = T ( u ) u ∼ p u ( u ) \mathbf{u} \sim p_u(\mathbf{u}) u ∼ p u ( u ) p x ( x ) = p u ( T − 1 ( x ) ) ∣ det J T − 1 ( x ) ∣ p_{\mathrm{x}}(\mathbf{x})=p_{\mathrm{u}}\left(T^{-1}(\mathbf{x})\right)\left|\operatorname{det} J_{T^{-1}}(\mathbf{x})\right| p x ( x ) = p u ( T − 1 ( x ) ) ∣ det J T − 1 ( x ) ∣
Flow-based Models 有多强的表达能力? 我们知道 p u ( u ) p_u(\mathbf{u}) p u ( u ) p u ( u ) p_u(\mathbf{u}) p u ( u ) p x ( x ) p_x(\mathbf{x}) p x ( x ) p x ( x ) > 0 p_x(\mathbf{x}) > 0 p x ( x ) > 0 x i x_i x i x < i x_{<i} x < i p x ( x ) p_x(\mathbf{x}) p x ( x )
p x ( x ) = ∏ i = 1 D p x ( x i ∣ x < i ) p_{\mathrm{x}}(\mathbf{x})=\prod_{i=1}^D p_{\mathrm{x}}\left(\mathbf{x}_i \mid \mathbf{x}_{<i}\right) p x ( x ) = i = 1 ∏ D p x ( x i ∣ x < i ) 假设变换 F F F x \mathbf{x} x z \mathbf{z} z z i \mathbf{z_i} z i x i \mathbf{x_i} x i
z i = F i ( x i , x < i ) = ∫ − ∞ x i p x ( x i ′ ∣ x < i ) d x i ′ = Pr ( x i ′ ≤ x i ∣ x < i ) \mathrm{z}_i=F_i\left(\mathrm{x}_i, \mathbf{x}_{<i}\right)=\int_{-\infty}^{\mathrm{x}_i} p_{\mathrm{x}}\left(\mathrm{x}_i^{\prime} \mid \mathbf{x}_{<i}\right) d \mathrm{x}_i^{\prime}=\operatorname{Pr}\left(\mathrm{x}_i^{\prime} \leq \mathrm{x}_i \mid \mathbf{x}_{<i}\right) z i = F i ( x i , x < i ) = ∫ − ∞ x i p x ( x i ′ ∣ x < i ) d x i ′ = Pr ( x i ′ ≤ x i ∣ x < i ) 很明显 F F F p x ( x i ∣ x < i ) d x i ′ p_x(\mathbf{x_i}| \mathbf{x}_{<i})dx_i' p x ( x i ∣ x < i ) d x i ′ F i F_i F i x j x_j x j J F ( x ) J_F(\mathbf{x}) J F ( x )
det J F ( x ) = ∏ i = 1 D ∂ F i ∂ x i = ∏ i = 1 D p x ( x i ∣ x < i ) = p x ( x ) > 0 \operatorname{det} J_F(\mathbf{x})=\prod_{i=1}^D \frac{\partial F_i}{\partial \mathbf{x}_i}=\prod_{i=1}^D p_{\mathrm{x}}\left(\mathbf{x}_i \mid \mathbf{x}_{<i}\right)=p_{\mathrm{x}}(\mathbf{x})>0 det J F ( x ) = i = 1 ∏ D ∂ x i ∂ F i = i = 1 ∏ D p x ( x i ∣ x < i ) = p x ( x ) > 0 因为 p ( x ) > 0 p(x) > 0 p ( x ) > 0 F F F
p z ( z ) = p x ( x ) ∣ det J F ( x ) ∣ − 1 = 1 p_z(\mathbf{z})=p_x(\mathbf{x})\left|\operatorname{det} J_F(\mathbf{x})\right|^{-1}=1 p z ( z ) = p x ( x ) ∣ det J F ( x ) ∣ − 1 = 1 即 z \mathbf{z} z
上述对 p ( x ) p(x) p ( x ) x i x_i x i x < i x_{<i} x < i ( x i , x < i ) (x_i, x_{<i}) ( x i , x < i ) p x ( x ) > 0 ∀ x ∈ R D p_x(\mathbf{x})> 0 \ \forall \mathbf{x} \in \mathbb{R}^D p x ( x ) > 0 ∀ x ∈ R D F F F F F F F − 1 F^{-1} F − 1 p z ( z ) p_z(\mathbf{z}) p z ( z ) p x ( x ) p_x(\mathbf{x}) p x ( x ) p ( x ) p(x) p ( x ) p ( u ) p(u) p ( u ) F − 1 F^{-1} F − 1 p z ( z ) p_z(\mathbf{z}) p z ( z ) p x ( x ) p_x(\mathbf{x}) p x ( x )
有限组合的变换 我们通过组合 K 个 transformation 得到 T 变换,令 z 0 = u \mathbf{z_0}=\mathbf{u} z 0 = u z K = x \mathbf{z_K}=\mathbf{x} z K = x
T = T K ∘ ⋯ ∘ T 1 z k = T k ( z k − 1 ) for k = 1 : K z k − 1 = T k − 1 ( z k ) for k = K : 1 log ∣ J T ( z ) ∣ = log ∣ ∏ k = 1 K J T k ( z k − 1 ) ∣ = ∑ k = 1 K log ∣ J T k ( z k − 1 ) ∣ \begin{aligned} T &=T_K \circ \cdots \circ T_1 \\ \mathbf{z}_k &=T_k\left(\mathbf{z}_{k-1}\right) \text { for } k=1: K \\ \mathbf{z}_{k-1} &=T_k^{-1}\left(\mathbf{z}_k\right) \text { for } k=K: 1 \\ \log \left|J_T(\mathbf{z})\right| &=\log \left|\prod_{k=1}^K J_{T_k}\left(\mathbf{z}_{k-1}\right)\right|=\sum_{k=1}^K \log \left|J_{T_k}\left(\mathbf{z}_{k-1}\right)\right| \end{aligned} T z k z k − 1 log ∣ J T ( z ) ∣ = T K ∘ ⋯ ∘ T 1 = T k ( z k − 1 ) for k = 1 : K = T k − 1 ( z k ) for k = K : 1 = log ∣ ∣ k = 1 ∏ K J T k ( z k − 1 ) ∣ ∣ = k = 1 ∑ K log ∣ J T k ( z k − 1 ) ∣ 我们可以将每个 T k T_k T k T k − 1 T_k^{-1} T k − 1 ϕ k \phi_k ϕ k f ϕ k f_{\phi_k} f ϕ k K L \mathrm{KL} KL T k T_k T k K L \mathrm{KL} KL T k − 1 T_k^{-1} T k − 1 f ϕ k f_{\phi_k} f ϕ k f ϕ k f_{\phi_k} f ϕ k f ϕ k f_{\phi_k} f ϕ k T k T_k T k T k − 1 T_k^{-1} T k − 1 k \mathrm{k} k f ϕ f_\phi f ϕ x \mathrm{x} x z \mathrm{z} z
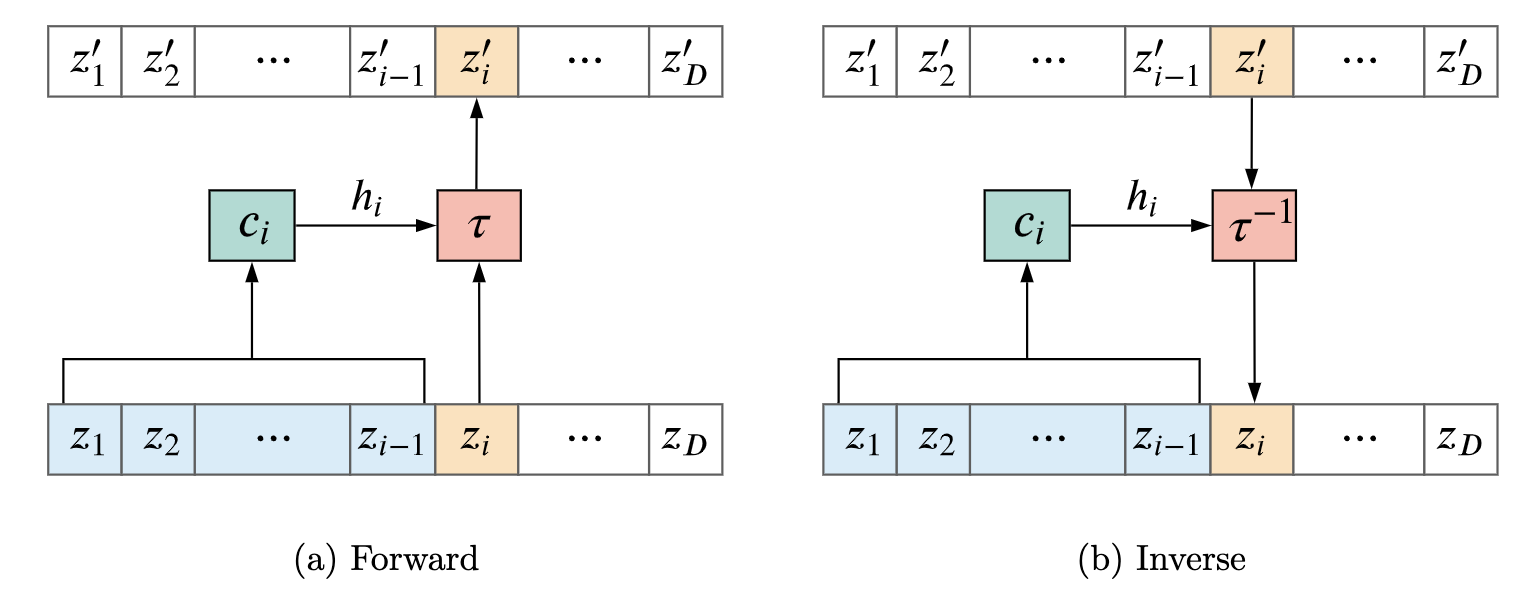
自回归流 Autoregressive flows 我们知道了在合理的情况下,我们可以使用一个下三角雅可比矩阵将任意的概率分布 p x ( x ) p_x(\mathbf{x}) p x ( x )
z i ′ = τ ( z i ; h i ) where h i = c i ( z < i ) \mathrm{z}_i^{\prime}=\tau\left(\mathrm{z}_i ; \boldsymbol{h}_i\right) \quad \text { where } \quad \boldsymbol{h}_i=c_i\left(\mathbf{z}_{<i}\right) z i ′ = τ ( z i ; h i ) where h i = c i ( z < i ) τ \tau τ c i c_i c i i \mathrm{i} i τ \tau τ h i , h i h_i, h_i h i , h i z i \mathbf{z}_i z i z i ′ \mathbf{z}_i^{\prime} z i ′ z < i \mathbf{z}_{<i} z < i f ϕ f_\phi f ϕ ϕ \phi ϕ τ \tau τ h i ) ∘ \left.h_i\right) \circ h i ) ∘
z i = τ − 1 ( z i ′ ; h i ) where h i = c i ( z < i ) \mathrm{z}_i=\tau^{-1}\left(\mathrm{z}_i^{\prime} ; \boldsymbol{h}_i\right) \quad \text { where } \quad \boldsymbol{h}_i=c_i\left(\mathbf{z}_{<i}\right) z i = τ − 1 ( z i ′ ; h i ) where h i = c i ( z < i ) 在正向计算中, 因为输入 z \mathbf{z} z h i h_i h i z ′ \mathbf{z}^{\prime} z ′ z i \mathbf{z}_i z i z < i \mathbf{z}_{<i} z < i z < i \mathbf{z}_{<i} z < i h i h_i h i z i ′ \mathbf{z}_i^{\prime} z i ′ z > i \mathbf{z}_{>i} z > i z ≤ i ′ \mathbf{z}_{\leq i}^{\prime} z ≤ i ′ z > i \mathbf{z}_{>i} z > i
J f ϕ ( z ) = [ ∂ τ ∂ z 1 ( z 1 ; h 1 ) 0 ⋱ L ( z ) ∂ τ ∂ z D ( z D ; h D ) ] J_{f_\phi}(\mathbf{z})=\left[\begin{array}{ccc} \frac{\partial \tau}{\partial z_1}\left(z_1 ; \boldsymbol{h}_1\right) & & \mathbf{0} \\ & \ddots & \\ \mathbf{L}(\mathbf{z}) & & \frac{\partial \tau}{\partial z_D}\left(\mathrm{z}_D ; \boldsymbol{h}_D\right) \end{array}\right] J f ϕ ( z ) = ⎣ ⎡ ∂ z 1 ∂ τ ( z 1 ; h 1 ) L ( z ) ⋱ 0 ∂ z D ∂ τ ( z D ; h D ) ⎦ ⎤ 它的行列式就是对角线元素乘积, 因此也非常好求
log ∣ det J f ϕ ( z ) ∣ = log ∣ ∏ i = 1 D ∂ τ ∂ z i ( z i ; h i ) ∣ = ∑ i = 1 D log ∣ ∂ τ ∂ z i ( z i ; h i ) ∣ \log \left|\operatorname{det} J_{f_\phi}(\mathbf{z})\right|=\log \left|\prod_{i=1}^D \frac{\partial \tau}{\partial \mathrm{z}_i}\left(\mathrm{z}_i ; \boldsymbol{h}_i\right)\right|=\sum_{i=1}^D \log \left|\frac{\partial \tau}{\partial \mathrm{z}_i}\left(\mathrm{z}_i ; \boldsymbol{h}_i\right)\right| log ∣ ∣ det J f ϕ ( z ) ∣ ∣ = log ∣ ∣ i = 1 ∏ D ∂ z i ∂ τ ( z i ; h i ) ∣ ∣ = i = 1 ∑ D log ∣ ∣ ∂ z i ∂ τ ( z i ; h i ) ∣ ∣
仿射自回归流(Affine autoregressive flows) 令 τ \tau τ
τ ( z i ; h i ) = α i z i + β i where h i = { α i , β i } \tau\left(\mathrm{z}_i ; \boldsymbol{h}_i\right)=\alpha_i \mathrm{z}_i+\beta_i \quad \text { where } \quad \boldsymbol{h}_i=\left\{\alpha_i, \beta_i\right\} τ ( z i ; h i ) = α i z i + β i where h i = { α i , β i } 只要 α i \alpha_i α i τ \tau τ α i = exp ( α i ~ ) \alpha_i=\exp \left(\tilde{\alpha_i}\right) α i = exp ( α i ~ ) α i ~ \tilde{\alpha_i} α i ~
log ∣ det J f ϕ ( z ) ∣ = ∑ i = 1 D log ∣ α i ∣ = ∑ i = 1 D α ~ i \log \left|\operatorname{det} J_{f_\phi}(\mathbf{z})\right|=\sum_{i=1}^D \log \left|\alpha_i\right|=\sum_{i=1}^D \tilde{\alpha}_i log ∣ ∣ det J f ϕ ( z ) ∣ ∣ = i = 1 ∑ D log ∣ α i ∣ = i = 1 ∑ D α ~ i 仿射自回归流虽然很简单, 但它的一大缺点是表达能力受限(Iimited expressivity), 假如 z z z z ′ z^{\prime} z ′
τ ( z i ; h i ) = w i 0 + ∑ k = 1 K w i k σ ( α i k z i + β i k ) where h i = { w i 0 , … , w i K , α i k , β i k } \tau\left(\mathrm{z}_i ; \boldsymbol{h}_i\right)=w_{i 0}+\sum_{k=1}^K w_{i k} \sigma\left(\alpha_{i k} \mathrm{z}_i+\beta_{i k}\right) \quad \text { where } \quad \boldsymbol{h}_i=\left\{w_{i 0}, \ldots, w_{i K}, \alpha_{i k}, \beta_{i k}\right\} τ ( z i ; h i ) = w i 0 + k = 1 ∑ K w ik σ ( α ik z i + β ik ) where h i = { w i 0 , … , w i K , α ik , β ik } 不像上面连续使用 K K K K K K σ ( ⋅ ) \sigma(\cdot) σ ( ⋅ ) h \mathrm{h} h 激活函数, 再线性组合 K种不同参数下的结果。一般使用反向传播优化参数, 缺点是该变换往往不可逆, 或者只能不断迭代求逆。
τ ( z i ; h i ) = ∫ 0 z i g ( z ; α i ) d z + β i where h i = { α i , β i } \tau\left(\mathrm{z}_i ; \boldsymbol{h}_i\right)=\int_0^{\mathrm{z}_i} g\left(\mathrm{z} ; \boldsymbol{\alpha}_i\right) d \mathrm{z}+\beta_i \quad \text { where } \quad \boldsymbol{h}_i=\left\{\boldsymbol{\alpha}_i, \beta_i\right\} τ ( z i ; h i ) = ∫ 0 z i g ( z ; α i ) d z + β i where h i = { α i , β i } g ( ⋅ ; α i ) g\left(\cdot ; \alpha_i\right) g ( ⋅ ; α i ) g ( z i ; α i ) g\left(\mathbf{z}_i ; \alpha_i\right) g ( z i ; α i ) g g g 2 L 2 L 2 L z i \mathbf{z}_i z i 2 L + 1 2 \mathrm{~L}+1 2 L + 1 2 L 2 L 2 L L L L τ \tau τ K K K L L L
τ ( z i ; h i ) = ∫ 0 z i ∑ k = 1 K ( ∑ ℓ = 0 L α i k ℓ z ℓ ) 2 d z + β i \tau\left(\mathrm{z}_i ; \boldsymbol{h}_i\right)=\int_0^{\mathrm{z}_i} \sum_{k=1}^K\left(\sum_{\ell=0}^L \alpha_{i k \ell} \mathrm{z}^{\ell}\right)^2 d \mathrm{z}+\beta_i τ ( z i ; h i ) = ∫ 0 z i k = 1 ∑ K ( ℓ = 0 ∑ L α ik ℓ z ℓ ) 2 d z + β i 参数 α \alpha α L = 0 L=0 L = 0 L > = 2 L>=2 L >= 2 2 L + 1 > = 5 2 L+1>=5 2 L + 1 >= 5 τ − 1 \tau^{-1} τ − 1
各种 conditioner c c c 虽然 c i c_i c i z i z_i z i c i c_i c i
循环自回归流(Recurrent autoregressive flows) 一种 Conditioner 参数共享的方法是使用循环神经网络RNN/GRU/LSTM来实现:
h i = c ( s i ) where s 1 = initial state s i = RNN ( z i − 1 , s i − 1 ) for i > 1 \begin{array}{ll} \boldsymbol{h}_i=c\left(\boldsymbol{s}_i\right) \text { where } & s_1=\text { initial state } \\ & \boldsymbol{s}_i=\operatorname{RNN}\left(\mathrm{z}_{i-1}, \boldsymbol{s}_{i-1}\right) \text { for } i>1 \end{array} h i = c ( s i ) where s 1 = initial state s i = RNN ( z i − 1 , s i − 1 ) for i > 1 RNN 被广泛用于在自回归模型条件分布中去共享参数。基于 RNN 的自回归模型有很多应用比如,分布估计,序列模型(NLP相关),视频/图像生成(PixelRNN[1] , VidePixelRNN[2] )。
在基于自回归流的 Flow 模型中,RNN 也被用于去共享参数,比如 Oliva et al. (2018) [4]、Kingma et al. (2016) [5],但是其相关的研究确比较少(我猜可能是效果不太好,RNN 不是太适合这个任务?)。 这种方法的主要缺点是计算不再能并行化, 因为计算 s i s_i s i s i − 1 s_{i-1} s i − 1
掩码自回归流(Masked autoregressive flows) 另一种参数共享,但是不依赖 RNN 的方式是通过 mask 来实现的。 这种方法使用一个单一,经典的前馈神经网络来实现 conditioner, 将 z \mathbf{z} z h 1 , . . . , h D h_1,...,h_D h 1 , ... , h D h i h_i h i z > = i z_{>=i} z >= i
为了让 h i h_i h i z > = i \mathbf{z}_{>=i} z >= i 但是这种缺点对于只需要正向的应用来说就不存在 )。
上面的计算过程是: 开始不知道 z z z z 0 z_0 z 0 h 1 \mathrm{h}_1 h 1 z 1 ′ z_1^{\prime} z 1 ′ z 1 z_1 z 1 z z z D D D z z z z ( < i ) z(<\mathrm{i}) z ( < i ) h i h_i h i h 1 h_1 h 1 z 1 z_1 z 1 z 1 z_1 z 1 h 2 h_2 h 2 z 2 z_2 z 2 D D D c c c f ( z ) = z ′ f(z)=z^{\prime} f ( z ) = z ′ z z z g ( z ) = f ( z ) − z ′ g(z)=f(z)-z^{\prime} g ( z ) = f ( z ) − z ′ z = z − a ∗ g ( z ) / g ′ ( z ) = z − a ∗ z=z-a * g(z) / g^{\prime}(z)=z-a * z = z − a ∗ g ( z ) / g ′ ( z ) = z − a ∗ ( f ( z ) − z ′ ) / J ) \left.\left(f(z)-z^{\prime}\right) / J\right) ( f ( z ) − z ′ ) / J )
z k + 1 = z k − α diag ( J f ϕ ( z k ) ) − 1 ( f ϕ ( z k ) − z ′ ) \mathbf{z}_{k+1}=\mathbf{z}_k-\alpha \operatorname{diag}\left(J_{f_\phi}\left(\mathbf{z}_k\right)\right)^{-1}\left(f_\phi\left(\mathbf{z}_k\right)-\mathbf{z}^{\prime}\right) z k + 1 = z k − α diag ( J f ϕ ( z k ) ) − 1 ( f ϕ ( z k ) − z ′ ) 我们使用 z ′ \mathbf{z}^{\prime} z ′ z 0 , f ϕ − 1 ( z ′ ) \mathbf{z}_0, f_\phi^{-1}\left(\mathbf{z}^{\prime}\right) z 0 , f ϕ − 1 ( z ′ ) 0 < α < 2 0<\alpha<2 0 < α < 2 z k \mathbf{z}_k z k
掩码自回归流有两个主要的优点。首先它正向推理的速度很快,给定一个 z \mathbf{z} z h 1 , . . . , h D h_1,...,h_D h 1 , ... , h D z ′ z' z ′ z i ′ = τ ( z i ; h i ) \mathrm{z}_i^{\prime}=\tau\left(\mathrm{z}_i ; \boldsymbol{h}_i\right) z i ′ = τ ( z i ; h i ) 掩码自回归流的缺点是它的反向计算速度很慢。 尽管掩码自回归流的反向计算速度很慢,但是其仍然是最流行的自回归Flow模型之一。
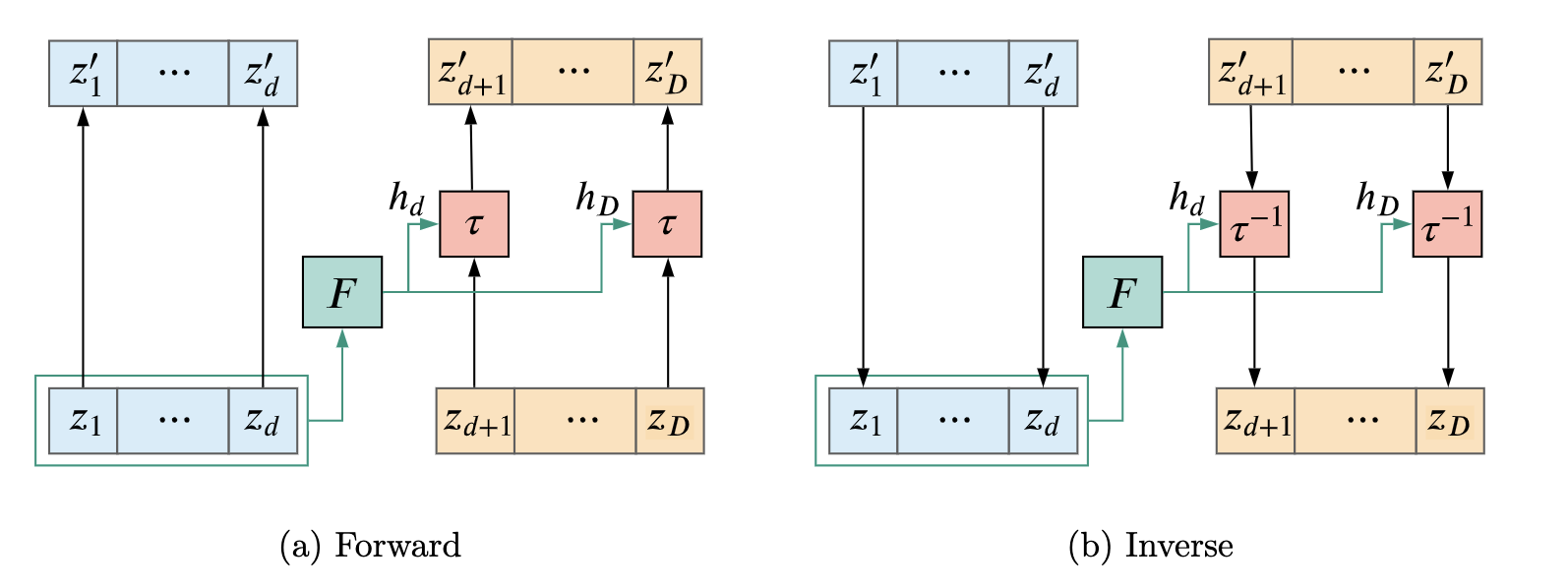
Coupling layers Coupling layers 是将 z z z d d d d + 1 ∼ D d+1 \sim D d + 1 ∼ D d d d h 1 ∼ h d h_1 \sim h_d h 1 ∼ h d z , h d + 1 ∼ h D z, h_{d+1} \sim h_D z , h d + 1 ∼ h D z < = d z<=d z <= d
z ≤ d ′ = z ≤ d ( h d + 1 , … , h D ) = N N ( z ≤ d ) z i ′ = τ ( z i ; h i ) for i > d \begin{aligned} \mathbf{z}_{\leq d}^{\prime} &=\mathbf{z}_{\leq d} \\ \left(\boldsymbol{h}_{d+1}, \ldots, \boldsymbol{h}_D\right) &=\mathrm{NN}\left(\mathbf{z}_{\leq d}\right) \\ \mathbf{z}_i^{\prime} &=\tau\left(\mathbf{z}_i ; \boldsymbol{h}_i\right) \text { for } i>d \end{aligned} z ≤ d ′ ( h d + 1 , … , h D ) z i ′ = z ≤ d = NN ( z ≤ d ) = τ ( z i ; h i ) for i > d 其雅可比矩阵左上角 d d d d dd ( D − d ) × ( D − d ) (D-d) \times(D-d) ( D − d ) × ( D − d )
J f ϕ = [ I 0 A D ] J_{f_\phi}=\left[\begin{array}{ll} \mathbf{I} & \mathbf{0} \\ \mathbf{A} & \mathbf{D} \end{array}\right] J f ϕ = [ I A 0 D ] 虽然 Coupling Layers 的计算效率更高, 但表达能力受限, 但我们可以通过堆叠多个 coupling layer并在每层对 z z z d d d d d d
Coupling Layer 和全自回归流是两种完全不同的实现。Coupling Layer 将 z \mathbf{z} z F F F z i z_i z i z < i z_{<i} z < i
Coupling Layer 的优点是计算速度快,但是相对应的是让模型的表达能力受到了限制。与循环或Mask自回归流不同,单个的 Coupling Layer 不再能够表示任何自回归转换。因此在使用 Coupling Layer 的时候需要堆叠多个 Coupling Layer,每个 Coupling Layer 都对 z \mathbf{z} z
Coupling Layer 由于其采样和密度估计的速度的过程都非常快,成为了目前最常用的变换函数。基于 Coupling Layer 的流可以用极大似然进行拟合,进而有效地进行采样。因此,Coupling Layer 经常用在图像、音频和视频等高维数据的生成模型中。
Autoregression Model 和 Autoregressive Flow 除了归一化流(Autoregressive Flow),另一类流行的高维分布模型是自回归模型(Autoregression Model),现在我们讨论一下两者有什么关联。
为了建立自回归模型,我们首先将 p x ( x ) p_x(\mathbf{x}) p x ( x )
p x ( x ) = ∏ i = 1 D p x ( x i ∣ x < i ) p_{\mathrm{x}}(\mathbf{x})=\prod_{i=1}^D p_{\mathrm{x}}\left(\mathrm{x}_i \mid \mathbf{x}_{<i}\right) p x ( x ) = i = 1 ∏ D p x ( x i ∣ x < i ) 下面我们使用参数 h i \mathbf{h}_i h i
p x ( x i ∣ x < i ) = p x ( x i ; h i ) , where h i = c i ( x < i ) p_{\mathbf{x}}\left(\mathbf{x}_i \mid \mathbf{x}_{<i}\right)=p_{\mathbf{x}}\left(\mathbf{x}_i ; \boldsymbol{h}_i\right), \quad \text { where } \quad \boldsymbol{h}_i=c_i\left(\mathbf{x}_{<i}\right) p x ( x i ∣ x < i ) = p x ( x i ; h i ) , where h i = c i ( x < i ) 比如 p x ( x i ; h i ) p_{\mathbf{x}}\left(\mathbf{x}_i ; \boldsymbol{h}_i\right) p x ( x i ; h i ) μ i \mu_i μ i σ i \sigma_i σ i c i c_i c i
那么自回归模型和自回归流有什么关系呢?我们可以将自回归模型看作是自回归流的一种特殊情况。所有的连续变量的自回归模型本质上都是具有单一自回归层的自回归流。综述论文里面还有对这块进行很详细的推导,有兴趣的可以去看原文
线性流 Linear Flows 在实践的过程中,基于Flow的模型有一个问题就是,一些目标变换可能更容易学习到,但是有一些变换就比较难学习到。这个问题在使用 Coupling Layer 的时候会被放大,因为其只会对一半的数据进行变换。这也是为什么 Coupling Layer 在处理的过程中需要将上下部分的数据进行调换,这样就可以保证数据的每个部分都能够被变换到。
为了解决这个问题,在实现的时候我们经常会使用 Permutation 操作:对输入的数据进行随机打乱。对于 Coupling Layer 这甚至是一个必要的操作。 Permute 需要是一个简单的可逆变换,同时其的 Jacobian 矩阵应该是1。Permutation 操作可以和可逆或者可微的变换相结合。 其中一种就是 Linear 变换。 Linear flow 本质上进行使用一系列的线性变换:
z ′ = W z \mathbf{z}^{\prime}=\mathbf{W} \mathbf{z} z ′ = Wz 其中 W \mathbf{W} W D × D D \times D D × D W \mathbf{W} W W \mathbf{W} W W \mathbf{W} W
一种直觉上的优化方法就是将 Permutation 的 W \mathbf{W} W W \mathbf{W} W O ( D 3 ) O(D^3) O ( D 3 ) W \mathbf{W} W W \mathbf{W} W
在自回归流中输出 z i z_i z i z < = i z_{<=i} z <= i
z ′ = W z z' = \mathbf{W}\mathbf{z} z ′ = Wz 雅克比矩阵就是 W \mathbf{W} W W \mathbf{W} W
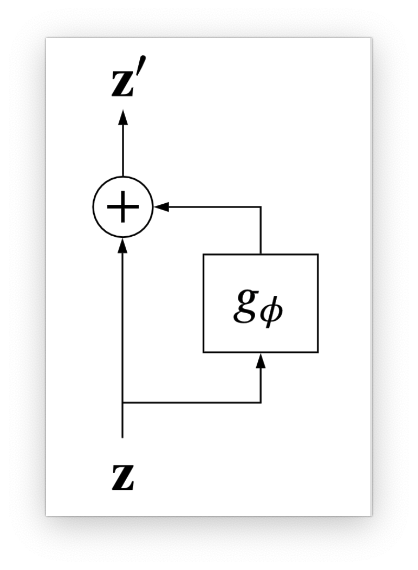
残差流 Residual Flows 残差流的计算公式如下:
z ′ = z + g ϕ ( z ) \mathbf{z}^{\prime}=\mathbf{z}+g_\phi(\mathbf{z}) z ′ = z + g ϕ ( z ) g ϕ g_\phi g ϕ
Contractive residual flows 构建满足 Lipschitz 连续条件,且 Lipschitz 常数小于1的变换F \mathbf{F} F
Residual flows based on the matrix determinant lemma A A A D × D D \times D D × D V 、 W V 、 W V 、 W D × M D \times M D × M M < D M<D M < D
det ( A + V W ⊤ ) = det ( I + W ⊤ A − 1 V ) det A \operatorname{det}\left(\mathbf{A}+\mathbf{V} \mathbf{W}^{\top}\right)=\operatorname{det}\left(\mathbf{I}+\mathbf{W}^{\top} \mathbf{A}^{-1} \mathbf{V}\right) \operatorname{det} \mathbf{A} det ( A + V W ⊤ ) = det ( I + W ⊤ A − 1 V ) det A 如果 A \mathrm{A} A O ( D 3 + D 2 M ) \mathcal{O}\left(D^3+D^2 M\right) O ( D 3 + D 2 M ) O ( M 3 + M 2 D ) \mathcal{O}\left(M^3+M^2 D\right) O ( M 3 + M 2 D )
Planar flow Planar flow 是一个单层神经网络,只有一个神经元 w
z ′ = z + v σ ( w ⊤ z + b ) J f ϕ ( z ) = I + σ ′ ( w ⊤ z + b ) v w ⊤ det J f ϕ ( z ) = 1 + σ ′ ( w ⊤ z + b ) w ⊤ v \begin{aligned} \mathbf{z}^{\prime} &=\mathbf{z}+\mathbf{v} \sigma\left(\mathbf{w}^{\top} \mathbf{z}+b\right) \\ J_{f_\phi}(\mathbf{z}) &=\mathbf{I}+\sigma^{\prime}\left(\mathbf{w}^{\top} \mathbf{z}+b\right) \mathbf{v} \mathbf{w}^{\top} \\ \operatorname{det} J_{f_\phi}(\mathbf{z}) &=1+\sigma^{\prime}\left(\mathbf{w}^{\top} \mathbf{z}+b\right) \mathbf{w}^{\top} \mathbf{v} \end{aligned} z ′ J f ϕ ( z ) det J f ϕ ( z ) = z + v σ ( w ⊤ z + b ) = I + σ ′ ( w ⊤ z + b ) v w ⊤ = 1 + σ ′ ( w ⊤ z + b ) w ⊤ v σ \sigma σ tanh \tanh tanh σ ′ \sigma^{\prime} σ ′ S S S w ⊤ v > − 1 S \mathbf{w}^{\top} \mathbf{v}>-\frac{1}{S} w ⊤ v > − S 1
Sylvester flow 将 Planar flow 推广到有 M 个神经元 W 就是 Sylvester flow , V ∈ R D × M , W ∈ R D × M , \mathbf{V} \in \mathbb{R}^{D \times M}, \mathbf{W} \in \mathbb{R}^{D \times M} , V ∈ R D × M , W ∈ R D × M b ∈ R M , S ( z ) \mathbf{b} \in \mathbb{R}^M, \mathrm{~S}(\mathbf{z}) b ∈ R M , S ( z ) σ ′ ( W ⊤ z + b ) \sigma^{\prime}\left(\mathbf{W}^{\top} \mathbf{z}+\mathbf{b}\right) σ ′ ( W ⊤ z + b )
z ′ = z + V σ ( W ⊤ z + b ) J f ϕ ( z ) = I + V S ( z ) W ⊤ det J f ϕ ( z ) = det ( I + S ( z ) W ⊤ V ) \begin{aligned} \mathbf{z}^{\prime} &=\mathbf{z}+\mathbf{V} \sigma\left(\mathbf{W}^{\top} \mathbf{z}+\mathbf{b}\right) \\ J_{f_\phi}(\mathbf{z}) &=\mathbf{I}+\mathbf{V S}(\mathbf{z}) \mathbf{W}^{\top} \\ \operatorname{det} J_{f_\phi}(\mathbf{z}) &=\operatorname{det}\left(\mathbf{I}+\mathbf{S}(\mathbf{z}) \mathbf{W}^{\top} \mathbf{V}\right) \end{aligned} z ′ J f ϕ ( z ) det J f ϕ ( z ) = z + V σ ( W ⊤ z + b ) = I + VS ( z ) W ⊤ = det ( I + S ( z ) W ⊤ V ) 实现中的问题 实现 Flow 通常相当于在计算和内存允许的情况下组合尽可能多的转换(使用更多的流模块)。 比如 Glow 就使用了 320 个子模块,并使用了 40 个 GPU 进行训练。在实现这些网络非常深的模型时,会遇到一些问题,本节主要对这些问题进行介绍。
Normalization 与使用基于梯度的方法训练的深度神经网络一样,规范化中间的 z k \mathbf{z_k} z k T k ∘ B N ∘ T k − 1 T_k \circ \mathrm{BN} \circ T_{k-1} T k ∘ BN ∘ T k − 1
多尺度结构 前面已经提到过,x \mathbf{x} x u \mathbf{u} u T T T
参考文献 [1] Aaron van den Oord, Nal Kalchbrenner, & Koray Kavukcuoglu (2016). Pixel Recurrent Neural Networks international conference on machine learning.
[2] Nal Kalchbrenner, Aaron van den Oord, Karen Simonyan, Ivo Danihelka, Oriol Vinyals, Alex Graves, & Koray Kavukcuoglu (2016). Video Pixel Networks international conference on machine learning.
[3] Junier B. Oliva, Avinava Dubey, Manzil Zaheer, Barnabás Póczos, Ruslan Salakhutdinov, Eric P. Xing, & Jeff Schneider (2018). Transformation Autoregressive Networks international conference on machine learning.
[4] Durk P. Kingma, Tim Salimans, Rafal Jozefowicz, Xi Chen, Ilya Sutskever, & Max Welling (2016). Improved Variational Inference with Inverse Autoregressive Flow neural information processing systems.
[5] Laurent Dinh, Jascha Sohl-Dickstein, & Samy Bengio (2016). Density estimation using Real NVP Learning.