损失函数与梯度下降
tip
上一节的CS231N的课程中介绍了KNN算法与线性分类器算法。其中线性分类算法还没有介绍如何去实现,本节课中我们将会定义损失函数以及根据这个损失函数去优化线性分类器。引用PPT中的一段话:
TODO
- Define a loss function that quantifies with the unhappiness with the scores across the training data
- Come up with a way of efficiently finding the parameters that minimize the loss function. (optimization)
损失函数
Multiclass SVM loss
损失函数公式
这个损失函数是SVM中使用的loss。
假设输入为
损失函数的定义如下:
其中 是预测正确类别的分数。举一个例子,比如我们现在算一个三分类的损失函数,有猫、汽车和青蛙三种类别。现在我们输入一张猫的图像,输出的结果是[cat:3.2, car:5.1, frog:-1.7],那么loss的计算过程就是:
L = max(0,5.1-3.2+1) + max(0,-1.7 - 3.2 + 1)
= max(0,2.9) + max(0,-3.9)
= 2.9 + 0
= 2.9

接下来有几个思考题:
- 当汽车的分数增加或减少1的时候,loss会有什么变化?
答:loss不会发生变化,因为即使汽车的预测分数变化了1计算的结果也还是0. 公式中的1其实一个安全冗余度,也就是说loss只会惩罚和类别分数相近的预测。
- loss的最小值和最大值是多少?
答:最小值就是0,比如像汽车那一项。最大值理论上是正无穷。
- 刚刚开始训练的时候权重, 这时loss是多少呢?
答:约等于分类错误的类别
- 现在的损失函数是把错误的类比进行计算,如果把正确的类别也考虑进来呢?
答:对于正确的预测那么损失会多加一个1。所有图片的预测loss都加了一个1,所以对于loss不会产生什么影响。
- 如果用求平均去代替求和会怎么样?
答:使用平均代替求和其实并不会发生太大的变化,因为我们无非就是在损失函数那里去除了一个固定的常数。
代码实现
# numpy代码实现multiclass SVM loss
def L_i_vectorized(x,y,W):
scores = W.dot(x)
margins = np.maximum(0,scores-scores[y]+1)
margins[y] = 0
loss_i = np.sum(margins)
return loss_i
正则化
“如无必要,勿增实体”,这是著名的奥卡姆剃刀原则。他的意思就是切勿浪费较多东西去做,用较少的东西,同样可以做好的事情。
添加正则项可以防止模型在训练集上表现的太好而导致其的模型泛化能力不强。 上面公式中的 是一个权重系数。
几个简单正则化
L2正则化:
L1正则化:
弹性网络(L1 + L2):
除了这些比较简单的正则化外,我们还有:Dropout、Batch normalization、Stochastic depth等等较为复杂的正则化方法。
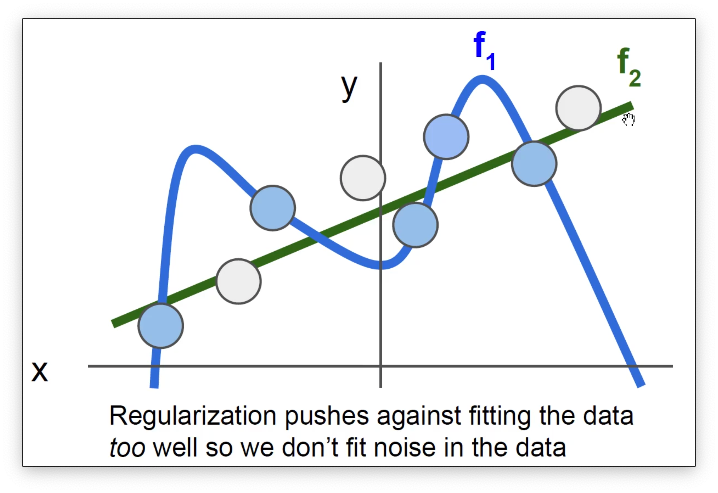
正则化可以帮助类似于 这样的过拟合的模型。
Softmax交叉熵损失
Softmax分类器
在前面提到的模型当中,我们每个类别的score都是一个数,而且这些数没有一个具体的范围。人们就希望可以将原始分类器分数解释为概率。这样就可以用信息论中的一些公式去优化算法。交叉熵也是信息论中的概念。
为了将score转化为概率,人们引入了Softmax。他的公式如下: Softmax的计算步骤主要分为两步:
- 将所有的score去指数
- 除以指数和

损失函数
Softmax交叉熵损失函数的公式如下:
这个公式和信息论中的自信息公式完全一样,但是他确实是根据公式一步一步去推导出来的。你也可以把Softmax损失函数理解为这个概率说包含的信息。
下面又有几个问题:
- 的最大值和最小值是什么?
答:参照一下log函数的图像就知道了,最大值就是正无穷,最小值就是0
- 一开始的时候每个类别的概率都是差不多的,Softmax交叉熵损失是多少呢?
答:
优化算法
优化算法的核心目的就是让loss最小化,你可以吧loss比较一个崎岖不平的山坡,我们的最终目的就是到达山底(loss最小的位置)。为了实现这个目标所采用的理论基础就是求导。
一维函数的求导公式如下: 在多维空间中,梯度是每个维上的(偏导数)向量,任何方向的斜率都是方向与梯度的点积。同时梯度下降法的方向是负梯度因为正的梯度是向上的,我们需要求loss的最小值所以是用的负梯度。
梯度下降的过程可以用如下代码表示:
while True:
weights_grad evaluate_gradient(loss_fun,data,weights)
weights += - step_size * weights_grad
SGD(Stochastic Gradient Descent)
如果我们每次去更新权重的时候都计算一遍所有的图片,有些时候N会非常大,计算时间也就会很长
SGD算法就是一次喂一小批的数据,一小批的数据肯定是没有总体数据具有代表性的。所以在训练的过程中loss可能会出现震荡的情况。但是毛主席说过:“道路是曲折的,前途是光明的”,SGD算法一般还是可以在最后达到一个比较好的收敛效果。
SGD的代码就可以表示为:
while True:
# 一次喂入256个数据
weights_grad evaluate_gradient(loss_fun,data,weights,256)
weights += - step_size * weights_grad
图像特征
在上一节的笔记中我有写到,使用线性分类器得到的权重提取到的都是比较浅层的特征。特征的选取在机器学习中是非常重要的一环,也有非常非常多相关的研究。
比如说对于下面这个数据,左边的数据如果选取x和y的坐标作为特征是很难将其区分的。但是如果把它转化为极坐标系的话就会很好进行区分。
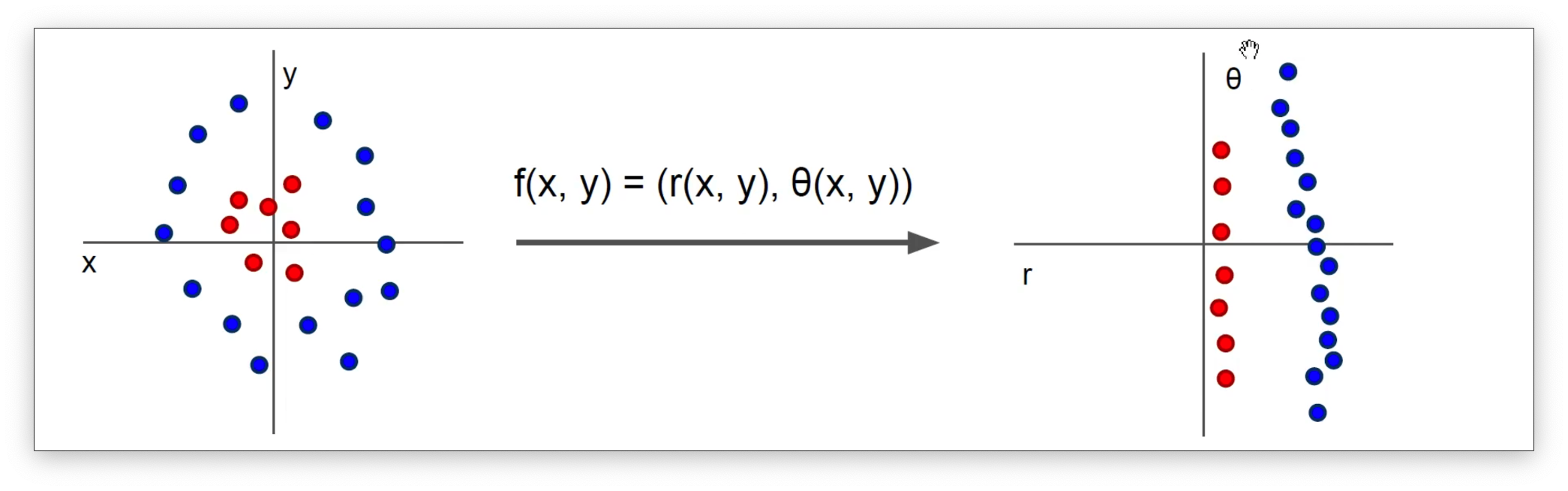
又比如HoG(Histogram of Oriented Gradients 方向梯度直方图),这也是一种提取图像特征的方法:

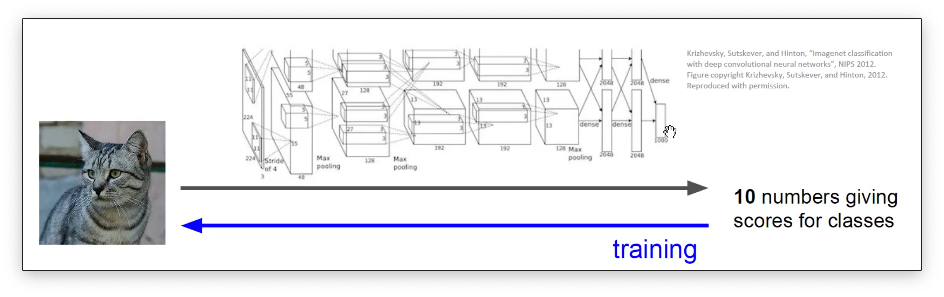
但是像HOG这样的特征其实属于人为设计的特征,在当代的卷积神经网络中。提取特征都是卷积神经网络替我们完成的。对于图像这样的数据我们不需要自己去构建特征,只需要用大量的数据来进行喂进去卷积神经网络就会进行帮我们提取特征了。
本次节课中我们学习了两种基础的损失函数,还学习了SGD优化器。最后课程介绍了图像特征相关的内容。这些都是深度学习中非常基础且重要的内容。