MKD: 基于多分辨率提取的异常检测
note
论文: Multiresolution Knowledge Distillation for Anomaly Detection (CVPR2021)
论文简介
当下的异常检测问题主要有两个方面:第一个方面是样本量不够大,不足以让卷积神经网络学习到一个通用的representation。第二点就是训练的过程中只有正常的样本被拿来训练,但是缺需要区分正常的样本和异常的样本。 这篇论文提出一种新的异常检测方式,它的核心实现是首先有一个训练好的大网络,然后通过知识蒸馏的方式去得到一个更加紧凑的小网络(Cloner),通过比较大网络和小网络的输出来确定样本是否异常。 不需要任何特殊的或强化的训练过程,这篇论文还将可解释性算法用于异常区域定位任务。
关键技术
这篇论文的思路其实都不难,但是提供了一个新的异常检测的方法。 该篇文章的核心思想可以被分为三个部分下面依次介绍:
知识蒸馏
首先我们有两个网络一个是cloner网络叫做C,还有一个是source网络叫做S,C经过训练之后需要能够模仿S的行为。与普通的知识蒸馏不同的是,普通的知识蒸馏要求的是让小网络能够模仿大网络的输出就可以了。但是在异常检测的任务里面,我们更希望小网络能够同时的模仿大网络的中间层,也就是让小网络尽可能的和大网络像。
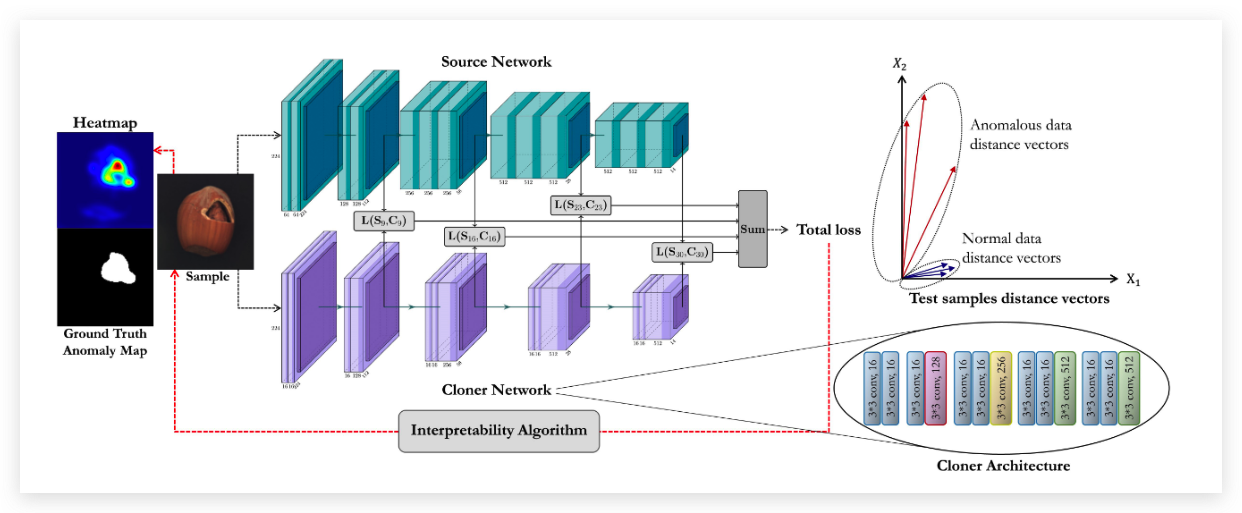
损失函数
损失函数主要由两部分组成,一类是预测层和输出层的值, 然后就是他们的梯度方向 。
的主要作用是让C和S中间激活层的欧拉距离尽可能的小。 CP表示critical layer, 表示CP的激活值。
此外,论文中还使用了方向损失函数来让激活向量的方向尽可能的接近。特别是在有Relu的神经网络里,基于相同欧拉距离的向量可能方向完全不同。所有的一切都是为了让S和C的行为更加的相似,因此论文中由使用了方向损失函数来控制激活层输出的方向。 的定义如下:
其中 vec(x) 是一个打平函数,用来将向量打平成一个一维的向量。这个公式其实就是一个余弦距离的计算公式。 最终将两个损失项合并起来就是完整的损失函数:
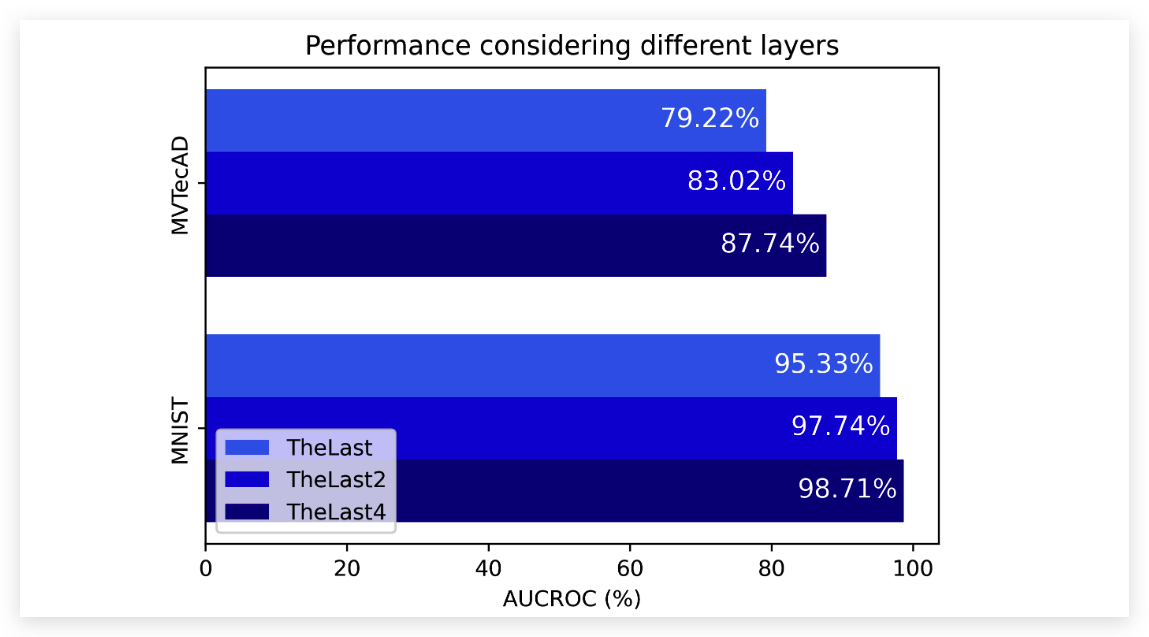
实验结果也表明,使用更多层去进行知识蒸馏的结果确实要更好。
异常检测
S和C预测的距离就可以用作异常检测,也就是 会被用于作为一个异常检测的阈值。
异常定位
已经有文献证明了,损失函数对输入的导数可以表示对每个像素的重要性。该篇论文中将损失函数对输入x的导数看做一个attention map。然后经过了高斯滤波和开闭后处理得到最终的Anomaly Localization Map。
总结
这篇工作开创性的将知识蒸馏用在了异常检测的领域,没有使用基于区域的训练和测试。整个流程不复杂,但是却简单有效。在知识蒸馏方面,通过设计了两个损失函数项来限制C学到的内容,在距离和方向上都与S相近。同时对中间层的输出结果进行监督,让C能够更好的学习S的知识。