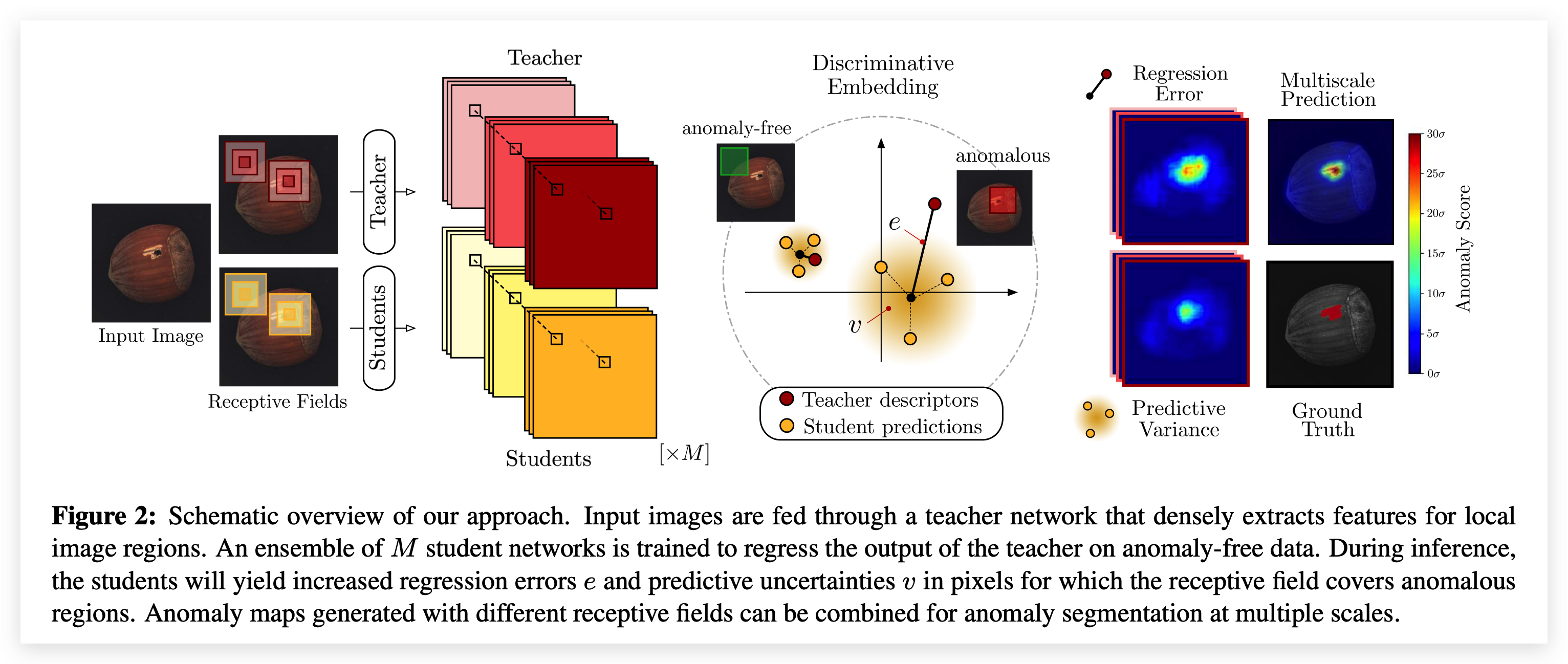
U-Student: Student–Teacher Anomaly Detection 论文概述
本文提出了一个名为 “Student-Teacher Anomaly Detection” 的新框架,利用Discriminative Embedding:首先Teacher网络(T)在大量自然图像(ImageNet)中进行预训练,Student网络(S)在无缺陷数据集上进行训练 (以Teacher网络的输出作为监督),比较S与T输出间的不同来判断该区域是否存在缺陷。 其中可以设置多个S,并且通过构造多尺度等方法构造ensemble。
关键技术 Teacher网络与Student网络具有相同架构,并且输入都是大小相等的图像块Patch,每个Patch在原图有着固定的感受野,利用 Fast Dense Local Feature Extraction 通过确定性转换应用于整幅图像(相比于将图片划分为一个个Patch来分别进行预测的方法,提升了速度,在后面的测试中也需要一次前向传播即可进行异常区域分割)。
训练Teacher Network T完全基于自然图像进行预训练,并且训练后不再更新参数,T输出D维的特征,该特征具有强语义性(semantically strong descriptors)。
损失函数分为三个部分:
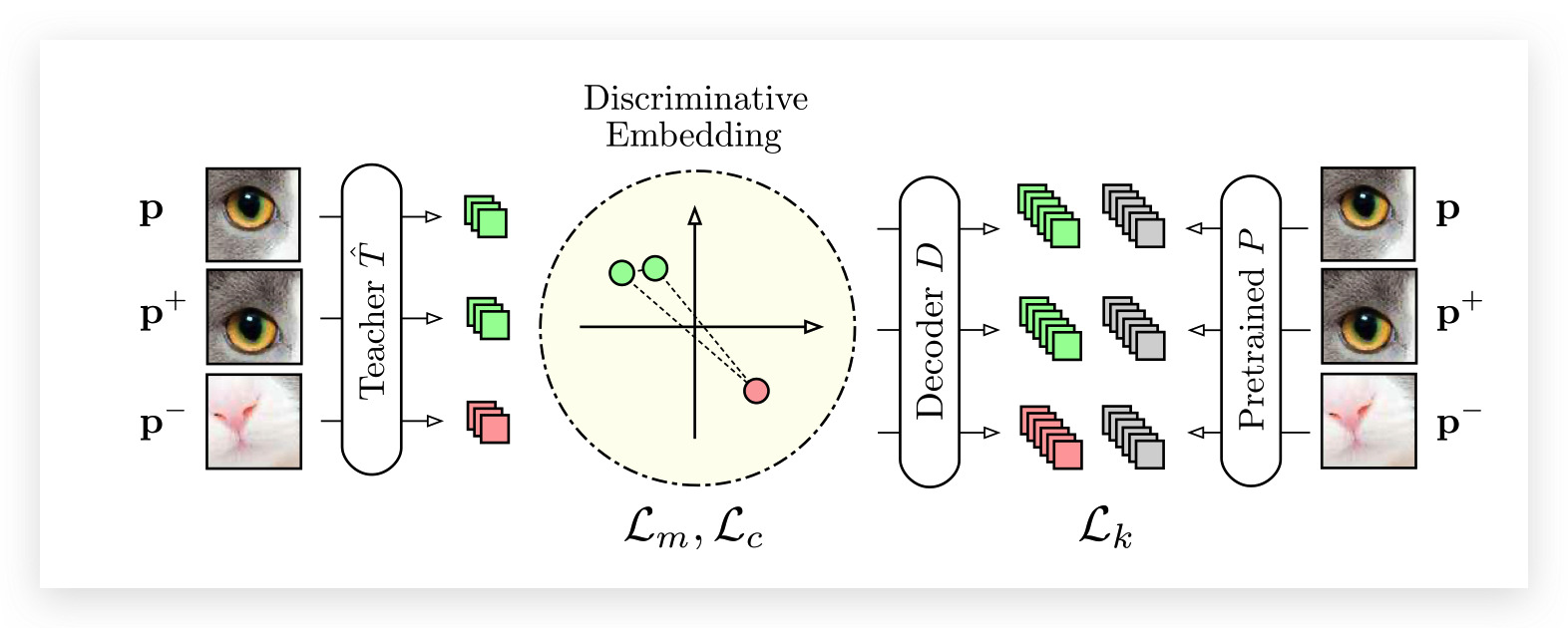
Knowledge Distillation 在这个阶段中,从预训练网络P汲取知识,增加一个全连接层 ,使T的输出维度与P一致,优化它们的L2 loss。
L k ( T ^ ) = ∥ D ( T ^ ( p ) ) − P ( p ) ∥ 2 \mathcal{L}_{k}(\hat{T})=\|D(\hat{T}(\mathbf{p}))-P(\mathbf{p})\|^{2} L k ( T ^ ) = ∥ D ( T ^ ( p )) − P ( p ) ∥ 2 Metric Learning 当预训练网络不好获取时,使用自监督学习的方式学习局部描述符。 主要使用三元学习来获取Discriminative Embedding,构造三元组(p,p+,p-),优化以下目标:
L m ( T ^ ) = max { 0 , δ + δ + − δ − } δ + = ∥ T ^ ( p ) − T ^ ( p + ) ∥ 2 δ − = min { ∥ T ^ ( p ) − T ^ ( p − ) ∥ 2 , ∥ T ^ ( p + ) − T ^ ( p − ) ∥ 2 } \begin{gathered} \mathcal{L}_{m}(\hat{T})=\max \left\{0, \delta+\delta^{+}-\delta^{-}\right\} \\ \delta^{+}=\left\|\hat{T}(\mathbf{p})-\hat{T}\left(\mathbf{p}^{+}\right)\right\|^{2} \\ \delta^{-}=\min \left\{\left\|\hat{T}(\mathbf{p})-\hat{T}\left(\mathbf{p}^{-}\right)\right\|^{2},\left\|\hat{T}\left(\mathbf{p}^{+}\right)-\hat{T}\left(\mathbf{p}^{-}\right)\right\|^{2}\right\} \end{gathered} L m ( T ^ ) = max { 0 , δ + δ + − δ − } δ + = ∥ ∥ T ^ ( p ) − T ^ ( p + ) ∥ ∥ 2 δ − = min { ∥ ∥ T ^ ( p ) − T ^ ( p − ) ∥ ∥ 2 , ∥ ∥ T ^ ( p + ) − T ^ ( p − ) ∥ ∥ 2 } Descriptor Compactness 通过最小化一个batch内的描述符相似度来增加紧凑度(compactness)同时减少不必要的冗余,c i , j c_{i,j} c i , j
L c ( T ^ ) = ∑ i ≠ j c i j \mathcal{L}_{c}(\hat{T})=\sum_{i \neq j} c_{i j} L c ( T ^ ) = i = j ∑ c ij 最后总的Loss为:
L ( T ^ ) = λ k L k ( T ^ ) + λ m L m ( T ^ ) + λ c L c ( T ^ ) \mathcal{L}(\hat{T})=\lambda_{k} \mathcal{L}_{k}(\hat{T})+\lambda_{m} \mathcal{L}_{m}(\hat{T})+\lambda_{c} \mathcal{L}_{c}(\hat{T}) L ( T ^ ) = λ k L k ( T ^ ) + λ m L m ( T ^ ) + λ c L c ( T ^ ) 训练Student Network 1、利用T提取计算训练集中所有描述符的均值与标准差,用于数据标准化(作用于T的输出)
2、构建M个S网络,每个S都为输入图像I输出特征描述符
具有限制感受野(大小为p)的网络S可以在一次前向传播过程中为I中每个像素点生成密集预测,而不需要切分为多个块P(r,c)
3、将S的输出建模为高斯分布,优化以下目标,其中S i S_i S i y T y^T y T
L ( S i ) = 1 w h ∑ ( r , c ) ∥ μ ( r , c ) S i − ( y ( r , c ) T − μ ) diag ( σ ) − 1 ∥ 2 2 \mathcal{L}\left(S_{i}\right)=\frac{1}{w h} \sum_{(r, c)}\left\|\mu_{(r, c)}^{S_{i}}-\left(\mathbf{y}_{(r, c)}^{T}-\boldsymbol{\mu}\right) \operatorname{diag}(\boldsymbol{\sigma})^{-1}\right\|_{2}^{2} L ( S i ) = w h 1 ( r , c ) ∑ ∥ ∥ μ ( r , c ) S i − ( y ( r , c ) T − μ ) diag ( σ ) − 1 ∥ ∥ 2 2 预测异常 将M个S都训练到收敛,构建混合高斯分布,平等加权每个S的输出。使用两种方法衡量一个像素点是否异常 :
① 回归误差 Regression Error (S与T之间的L2距离)
e ( r , c ) = ∥ μ ( r , c ) − ( y ( r , c ) T − μ ) diag ( σ ) − 1 ∥ 2 2 = ∥ 1 M ∑ i = 1 M μ ( r , c ) S i − ( y ( r , c ) T − μ ) diag ( σ ) − 1 ∥ 2 2 \begin{aligned} e_{(r, c)} &=\left\|\boldsymbol{\mu}_{(r, c)}-\left(\mathbf{y}_{(r, c)}^{T}-\boldsymbol{\mu}\right) \operatorname{diag}(\boldsymbol{\sigma})^{-1}\right\|_{2}^{2} \\ &=\left\|\frac{1}{M} \sum_{i=1}^{M} \boldsymbol{\mu}_{(r, c)}^{S_{i}}-\left(\mathbf{y}_{(r, c)}^{T}-\boldsymbol{\mu}\right) \operatorname{diag}(\boldsymbol{\sigma})^{-1}\right\|_{2}^{2} \end{aligned} e ( r , c ) = ∥ ∥ μ ( r , c ) − ( y ( r , c ) T − μ ) diag ( σ ) − 1 ∥ ∥ 2 2 = ∥ ∥ M 1 i = 1 ∑ M μ ( r , c ) S i − ( y ( r , c ) T − μ ) diag ( σ ) − 1 ∥ ∥ 2 2 ② 预测不确定性 Predictive Uncertainty (S中的标准差)
v ( r , c ) = 1 M ∑ i = 1 M ∥ μ ( r , c ) S i ∥ 2 2 − ∥ μ ( r , c ) ∥ 2 2 v_{(r, c)}=\frac{1}{M} \sum_{i=1}^{M}\left\|\boldsymbol{\mu}_{(r, c)}^{S_{i}}\right\|_{2}^{2}-\left\|\boldsymbol{\mu}_{(r, c)}\right\|_{2}^{2} v ( r , c ) = M 1 i = 1 ∑ M ∥ ∥ μ ( r , c ) S i ∥ ∥ 2 2 − ∥ ∥ μ ( r , c ) ∥ ∥ 2 2 结合两种分数1和2,最后的异常分数为:
e ~ ( r , c ) + v ~ ( r , c ) = e ( r , c ) − e μ e σ + v ( r , c ) − v μ v σ \tilde{e}_{(r, c)}+\tilde{v}_{(r, c)}=\frac{e_{(r, c)}-e_{\mu}}{e_{\sigma}}+\frac{v_{(r, c)}-v_{\mu}}{v_{\sigma}} e ~ ( r , c ) + v ~ ( r , c ) = e σ e ( r , c ) − e μ + v σ v ( r , c ) − v μ 其中 μ \mu μ σ \sigma σ
多尺度异常分割 由于网络架构中的感受野大小一定,如果感受野过大而异常区域过小,那么提取出来的特征基本为正常,无法对异常区域进行分割。因此,构建多个不同感受野的Student-Teacher网络对,将输出进行融合后作为最终的检测结果。
1 L ∑ l = 1 L ( e ~ ( r , c ) ( l ) + v ~ ( r , c ) ( l ) ) \frac{1}{L} \sum_{l=1}^{L}\left(\tilde{e}_{(r, c)}^{(l)}+\tilde{v}_{(r, c)}^{(l)}\right) L 1 l = 1 ∑ L ( e ~ ( r , c ) ( l ) + v ~ ( r , c ) ( l ) )
这篇文章的作者团队就是CVPR19提出Mvtec AD这个数据集的那批人,文章的脉络很清楚。最主要的创新在于将Student-Teacher架构引入异常检测领域,此外,也将迁移学习中的Metric Learning和Knowledge Distillation应用了进来,思想很新颖。
文章提出了一个新的指标来做实验,所以缺乏与其他工作的对比,不过谁让人家是顶会呢,最后这个指标也难免要被大家follow。其次的话,就是分块以及输入图像多尺度做法还是显得比较笨重,可以进一步优化 。 同时,S只模仿了T最后一层的输出,缺乏了对教师网络的充分利用,这也导致了它需要使用自监督等训练方式。